
Understanding CISSP Domain 2: Asset Security

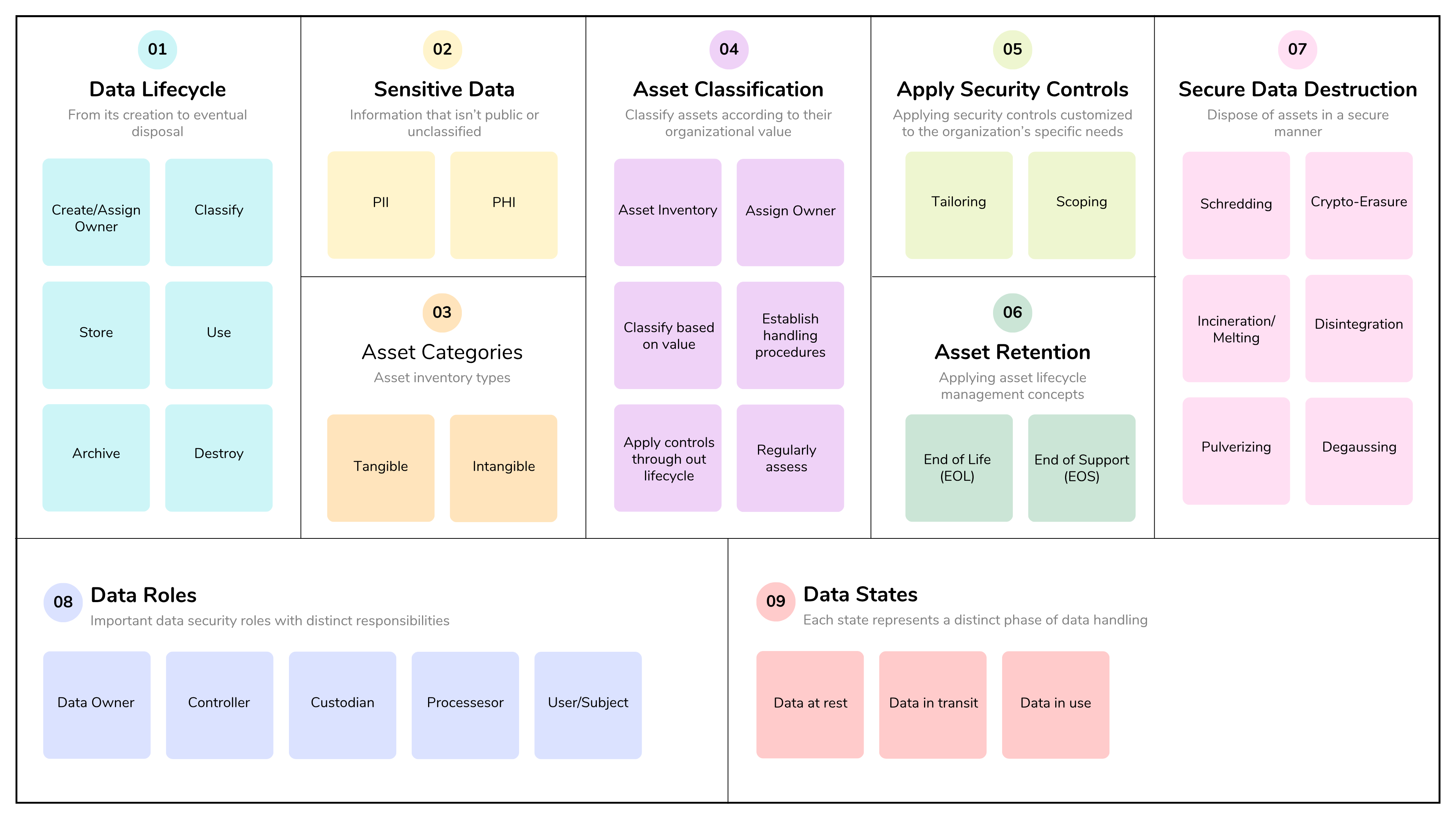
Asset Security focuses on protecting an organization’s valuable information and assets by managing their entire lifecycle, from identification and classification to proper handling, storage, retention, and secure disposal. While the concepts are easy to understand, implementation can be difficult, especially for large organizations with many assets to protect.
Key aspects of asset security include maintaining a comprehensive asset inventory, assigning ownership for accountability, classifying based on sensitivity, and establishing secure handling procedures for data at rest, in transit, and in use. Implementing secure handling procedures and appropriate security controls helps ensure the confidentiality, integrity, and availability of important assets.
Let’s dive into the domain and cover the material by following the ISC2 exam outline.
2.1 Identify and classify information and assets
Asset security is all about protecting what matters most to an organization - its data, the systems and hardware used to process it, and the media on which it resides. The domain’s focus is on identifying, classifying, and managing these assets throughout their lifecycle.
Data classification
Data classification is the process of organizing data into categories based on its sensitivity, value, and potential impact if it were to be compromised. It’s about understanding the value of the data and assigning the level of protection required based on that value.
Referring back to our discussion in Domain 1, remember that a security policy is a document that defines the scope of security needed by the organization, and data classifications are usually included in a security or data policy. An associated policy should discuss assets that require protection and the extent to which security solutions should go to provide the necessary protection.
Categorization means sorting assets into defined classes. Systematic categorization enables the determination of the appropriate security controls, protection levels, handling procedures, and resource allocation required for each data type, ensuring it receives the correct level of security.
Some of the benefits of data classification include:
Risk Management: It enables better risk assessment by identifying sensitive data and assessing the potential risks associated with its unauthorized disclosure or loss.
Tailored Security Controls: Classification allows for the application of security controls (like encryption or access restrictions) that are appropriate for each data type’s sensitivity, for instance, ensuring public data is lightly protected while sensitive financial or PII is rigorously secured.
Data Lifecycle Management: A foundational step for managing the data lifecycle, classification ensures proper protection is applied at every stage, from creation to destruction.
Resource Optimization: By understanding data’s value, organizations can allocate security resources more efficiently, focusing significant protection on what’s critical rather than over-protecting low-value data.
Regulatory Compliance: Data classification helps ensure compliance with laws and regulations (like HIPAA) by identifying what data requires specific handling, privacy protections, and reporting.
Impact Assessment: Classification provides context for understanding the potential business and reputational impact if data were compromised, which guides the rigor of security measures.
Clear Responsibilities: The process helps define roles and responsibilities, assigning data owners who understand the data’s criticality and can make informed decisions about its classification and handling. It also ensures that users can easily understand the classification level of data and handle it appropriately. When users understand the value of data, they are more likely to take appropriate steps to protect and manage it effectively.
Sensitive data is any information that isn’t public or unclassified. Sensitive data can include information that is important for the organization to protect due to its value or to comply with existing laws and regulations. Two basic types of sensitive data you should be familiar with for the exam:
Personally Identifiable Information (PII): any information that can identify an individual, including:
information that can be used to distinguish or trace an individual‘s identity, such as name, social security number, date and place of birth, mother‘s maiden name, or biometric records;
any other information that is linked or linkable to an individual, such as medical, educational, financial, and employment information.
Protected Health Information (PHI): any health-related information in any form that can be related to a specific person. See HIPAA coverage in Domain 1.
Organizations often use labels (AKA security labeling) attached to sensitive digital assets to help users easily identify their classification. Physical labels can also be used to identify asset media or systems that process sensitive data.
A data classification policy should:
Begin with an overarching data policy, which provides the foundation and direction for the data classification policy.
Consider, as part of policy development:
Who requires access to the data.
How access needs may change over time.
How long data should be retained.
Requirements for secure data disposal.
Be supported by related data retention, destruction, and archiving policies.
Clearly define roles and responsibilities for maintaining and enforcing the policy.
Identify and categorize all types of asset media, such as digital files, storage media, or paper records.
Include the factors that determine the data’s value, as these influence how assets should be protected.
Address asset liability and the potential consequences of regulatory oversight or non-compliance.
Reference relevant industry standards and explain how compliance (or lack thereof) can affect the organization’s reputation.
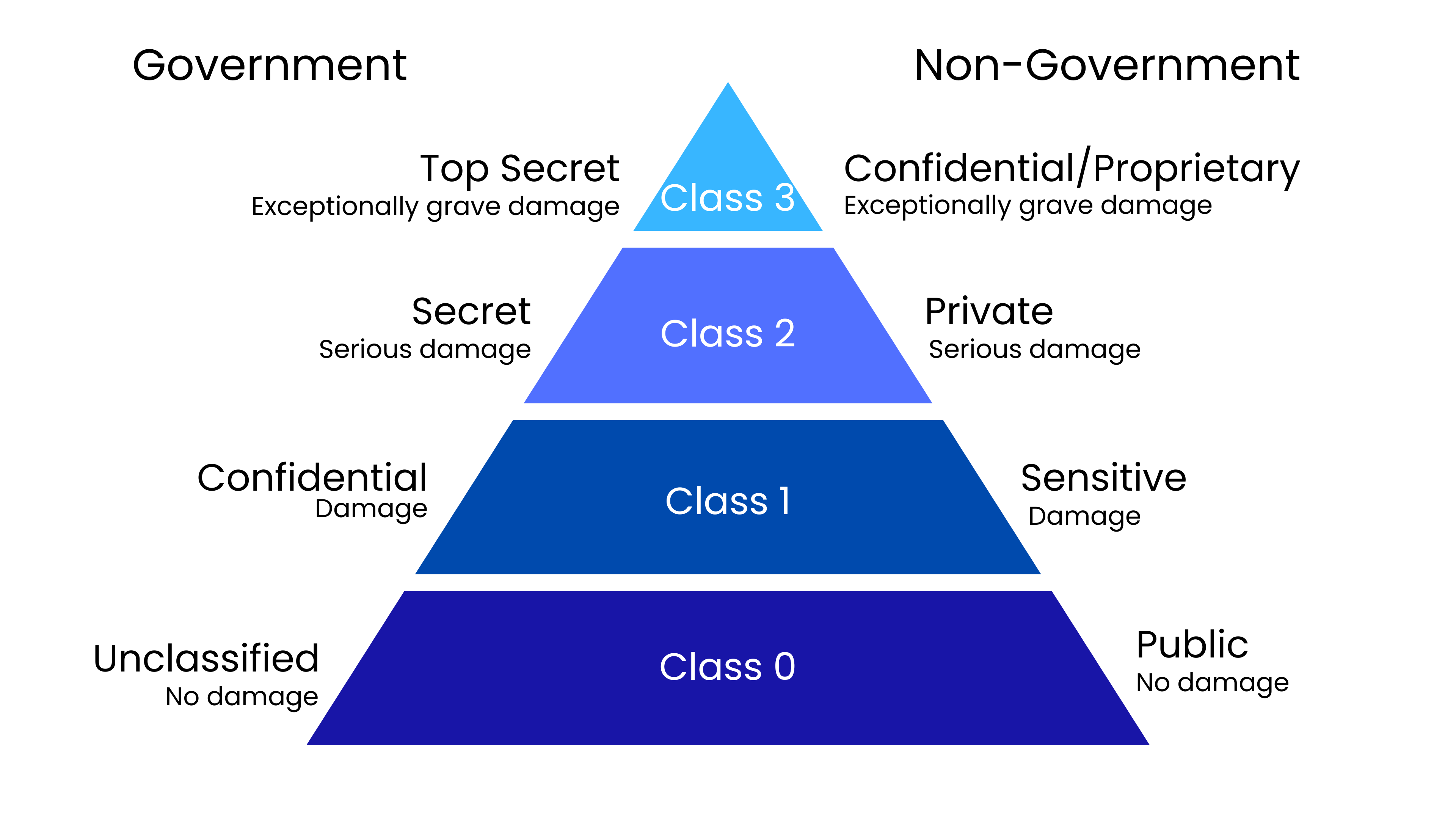
Government data classification is based on potential harm to national security, including confidentiality (the potential damage to national security if information is disclosed) and criticality (the potential damage if the data is unavailable).
Government classification labels include:
Unclassified: not sensitive, or not expected to damage national security if disclosed.
Confidential: the confidential label is “applied to information, the unauthorized disclosure of which reasonably could be expected to cause damage to the national security.”
Secret: if disclosed, could cause serious damage to national security.
Top Secret: if disclosed, could cause massive or exceptional damage to national security.
Non-government organizations use labels such as the following:
Confidential/Proprietary: often used only within the organization, and, in the case of unauthorized disclosure, results in serious consequences.
Private: may include personal information, such as credit card data and bank accounts; unauthorized disclosure can be disastrous.
Sensitive: needs precautions to ensure confidentiality and integrity.
Public: can be viewed by the general public and, therefore, the disclosure of this data would not cause damage.
Note that many organizations use their own unique classifications.
Asset Classification
To apply appropriate security measures, organizations need to understand the value and sensitivity of each asset. The word ‘value’ here reflects not only a potential monetary amount, but also the impact that the loss or unauthorized disclosure of an asset would have on the organization.
Determining the value of an asset is a key part of data and information lifecycle management, and it drives how assets are classified, protected, and managed.
Here’s a breakdown of what helps an organization determine asset value:
1. Business Impact
How critical is the asset to achieving organizational goals or supporting key business processes?
Ask: If this asset were lost, unavailable, or compromised, how would it impact operations, revenue, or productivity?
Assets essential to mission-critical operations or revenue generation are typically high-value.
2. Cost of Replacement or Loss
What would it cost (in time, money, and effort) to rebuild, reacquire, or restore the asset?
This includes direct costs (hardware, software, labor) and indirect costs (lost opportunities, downtime, reputation damage).
3. Sensitivity and Confidentiality
Does the asset contain sensitive or proprietary information, such as trade secrets, personal data, or financial details?
The more confidential the information, the higher its value — and the stronger the protection required.
4. Regulatory and Legal Requirements
Are there laws or regulations (e.g., GDPR, HIPAA, SOX) governing how this asset must be handled or protected?
Non-compliance can result in fines or legal penalties, increasing the asset’s risk — and therefore its value to the organization.
5. Impact on Reputation and Trust
Would the loss, alteration, or exposure of this asset damage customer trust or brand reputation?
Reputational impact often exceeds financial loss and must be factored into valuation.
6. Competitive Advantage
Does the asset provide an edge over competitors, such as proprietary data, algorithms, or product designs?
Information that differentiates the organization in the market carries strategic value.
7. Time Sensitivity and Availability Requirements
How long can the organization function without this asset?
Assets critical to real-time operations or requiring high availability (e.g., SCADA systems, payment gateways) have greater operational value.
Asset classification involves assigning assets a level of protection commensurate with their value to the organization. The asset classification process includes:
Begin with a comprehensive asset inventory to identify and document all information assets.
Assign an owner responsible for determining the appropriate classification, which guides all subsequent lifecycle activities.
Assign a classification immediately upon the asset’s creation, collection, or update, categorizing the asset into defined classes based on its value, sensitivity, and criticality to the organization.
Establish handling procedures appropriate to each classification level to ensure consistent safeguarding of assets.
Apply controls throughout the asset’s lifecycle, and regularly assess and review classifications, recognizing that classification is an ongoing process that must adapt to changes in business needs, regulations, or asset value.
2.2 Establish information and asset handling requirements
Asset handling procedures are established based on the information and asset classification. These procedures help mitigate risks associated with who and how assets are moved, stored, and retrieved during their lifecycle.
The following considerations help achieve the data and asset handling goal of preventing data loss and breaches:
Policies and procedures need to be created to ensure people understand how sensitive data and assets should be handled.
Policies providing requirements for labeling, storage, use, and disposal of sensitive data, systems, and media should be communicated to employees and any third-party controllers or handlers.
Controls (i.e., logging, monitoring, and auditing) should be put in place to verify that sensitive information is handled appropriately.
On-going monitoring and incident response for asset mishandling should be implemented, and incidents should be quickly investigated and corrective actions taken to prevent a recurrence.
2.3 Provision information and assets securely
The secure provision of information and assets starts with assigning ownership. It’s also important to maintain an accurate asset inventory and implement appropriate asset management practices throughout the asset's lifecycle, including the use of secure hardware and software provisioning, as well as the establishment of security control baselines.
A security control baseline is a standardized, minimum set of security controls and configurations for an information system, serving as a foundational reference point to ensure confidentiality, integrity, and availability of data and systems. Baselines are categorized by the system’s impact level (typically using categories of low, moderate, or high) and help monitor for deviations, manage risk, and maintain compliance with policies and regulations. See NIST SP 800-53 for more in-depth guidance.
Once the organization has identified and classified its assets, security baselines provide a starting point to ensure a minimum level of security. A common baseline use is imaging, where a single system set up with desired settings is imaged and deployed to other systems. After deploying a system in a secure state, it should be audited periodically to ensure it remains secure.
After selecting a control baseline, the organization should fine-tune it with a tailoring and scoping process (see below).
Information and asset ownership
Assigning information and asset ownership is a key requirement for protection accountability. The owner is the person or role who has ultimate organizational accountability for the protection of an asset. Owners are responsible for classifying and ensuring appropriate security controls are in place to protect these assets.
Key aspects of information and asset ownership include:
Clear Assignment of Ownership: Every asset must have a designated owner who is clearly identified and accountable for its protection. Assigning an owner is the first step in the classification process.
Accountability: The owner is ultimately accountable for the asset’s security and must ensure it is protected according to its classification and value to the organization.
Classification: The asset owner is responsible for classifying the information or asset based on its value, sensitivity, and the potential impact of unauthorized access, disclosure, or loss.
Defining Handling Requirements: Ownership involves establishing and enforcing the specific handling requirements for data, including markings, labeling, storage, and disposal, to align with the asset’s classification.
Information and Asset Lifecycle Management: The owner’s responsibilities extend across the entire asset lifecycle, from acquisition and processing to retention and secure destruction.
Security Controls and Compliance: Owners ensure that appropriate security controls are implemented to protect assets and that all handling and processing complies with relevant privacy laws and regulations.
Asset inventory (e.g., tangible, intangible)
Maintaining an accurate asset inventory is crucial because you can’t protect what you don’t know you have. It provides a foundational understanding of your organization’s attack surface, enabling informed risk and vulnerability management, supporting compliance efforts, and ensuring proper classification and ownership of assets. Without it, organizations face increased security risks from outdated systems, potential loss of valuable data and resources, and an inability to respond effectively to security incidents.
Some important points about asset inventory:
An asset inventory should be a complete list of all asset types (tangible and intangible)
Tangible assets are things like hardware, devices, and physical documents.
Intangible assets include software, licenses, and intellectual property (e.g., patents, copyrights, etc.).
Asset management
Asset management is a critical component of the Asset Security domain, ensuring that all information assets—whether physical, digital, or intangible—are properly identified, classified, handled, and protected throughout their lifecycle. Developing an asset management plan or program is an important first step.
2.4 Manage data lifecycle
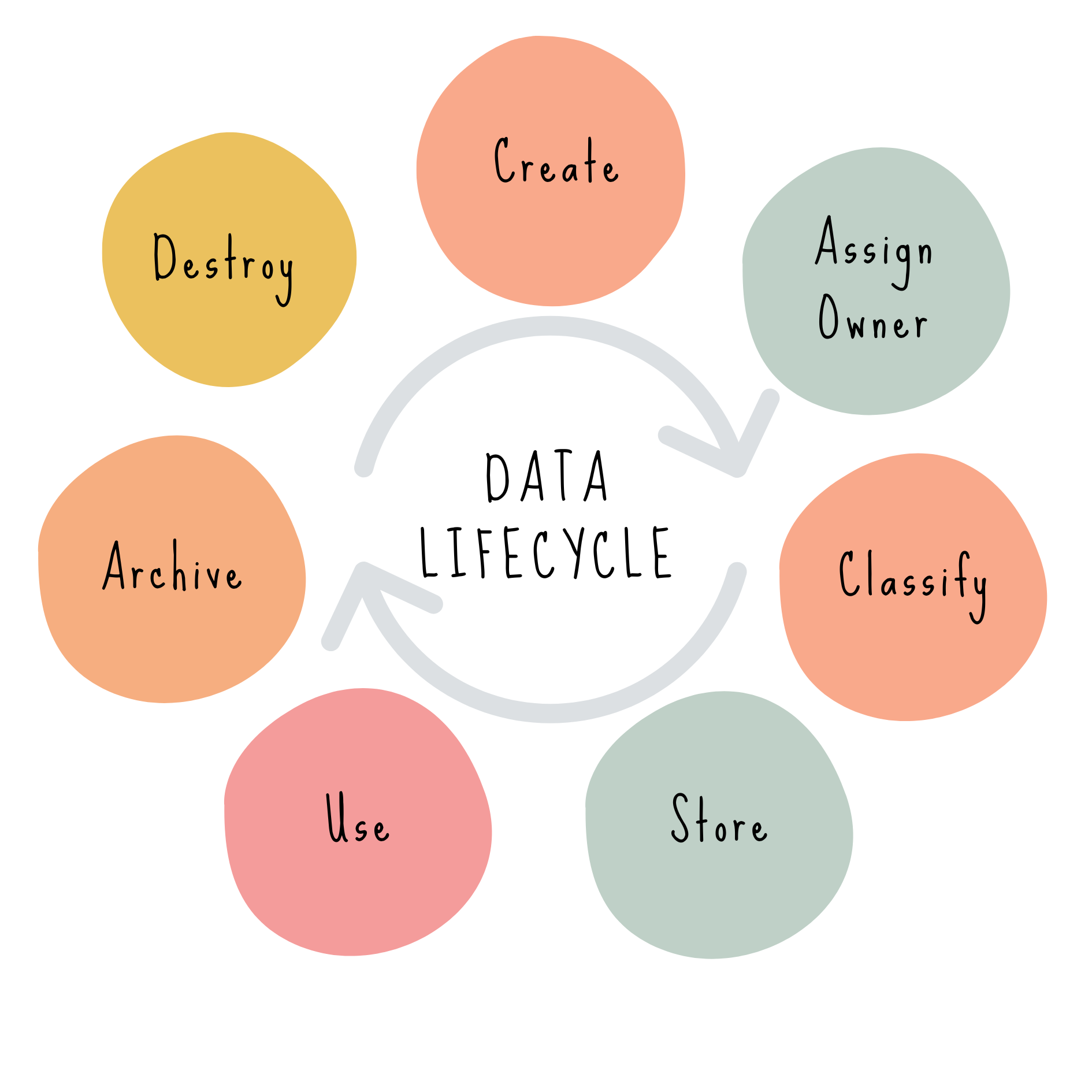
The data lifecycle is founded on the principle that proper controls should be in place at each point. You should be familiar with the concept, the general order of steps, and the key considerations for each.
The data lifecycle is the comprehensive process that data undergoes, from its creation to its eventual disposal. As a reference, take a look at the CSA’s version of the data lifecycle which includes 6 steps: create, store, use, share, archive, and destroy.
I’m using a slightly modified version that takes into account the considerations in this domain, for instance, ensuring that an owner is assigned at creation, and combining “share” as a normal component of the “use” step.
Data Lifecycle: Key steps:
Create: Data is generated, collected, or received by an organization (e.g., entering customer data, receiving a contract, generating a report).
Assign Owner: A person or role is designated as the data owner, who is responsible for:
Defining classification
Ensuring protection
Ensuring compliance with regulations and policies
Rule: Owners decide the rules, custodians implement them, users follow them.
Classify: Data is assigned a category, labeled according to its sensitivity, value, and criticality to the organization.
Exam Insight: Identify and categorize data as early as possible to enable proper protection. Classification supports risk-based data handling.
Store: Data is protected at rest by appropriate controls based on its classification.
Concern: Ensure confidentiality, integrity, and availability (CIA triad) of stored data.
Use: Data is protected by appropriate encryption in transit, and in-use (in-motion) — often via TLS.
Tip: Usage must adhere to acceptable use policies and comply with relevant data protection and privacy laws.
Archive: Data is moved to long-term storage when it’s no longer actively used but still must be retained.
Maintain integrity.
Protect archived data with equal controls, and include original log data as possible and appropriate.
Define retention scheduled (based on legal or business requirement).
Note: Archived data is often a target — keep it encrypted and access-limited.
Destroy: Data is securely and permanently deleted or destroyed as soon as it is no longer needed.
Destroyed data should not be retrievable using forensic tools and techniques.
Ensure compliance with retention and destruction policies.
Maintain audit trails or certificates of destruction, as required.
Exam Focus: Improper destruction = high risk of data breaches, exfiltration, and regulatory violations.
Data roles (i.e., owners, controllers, custodians, processors, users/subjects)
Data owner: the person or role accountable for data security, who determines classification, categorization, and how data is used, protected, and destroyed.
Data controller: the organization or person who decides what data to process and how to process it. They are responsible for ensuring compliance with regulatory requirements and implementing appropriate security controls based on category.
Data custodian: delegated responsibility from the system owner for properly storing and protecting data on a day-to-day basis. They are responsible for protecting data through maintenance activities, such as backup, archiving, and data recovery, thereby preventing the loss or corruption of data.
Data processor: an entity working on behalf (or at the direction) of the data controller that carries out processing tasks. They have a responsibility to protect the privacy of the data and not use it for any purpose other than as directed by the data controller.
Users/Subject: any person who is authorized to access the data to accomplish tasks. They are responsible for adhering to security policies and procedures to safeguard the data.
Data collection
Methods used to collect data should consider privacy implications, a clear purpose for the data, and its confidentiality and integrity.
Data collection guideline: if data doesn’t have a clear business purpose, don’t collect it. If required, ensure that privacy implications are understood and that user consent is obtained.
Data security: use secure collection methods for data in transit, use, and storage.
Data confidentiality and integrity: ensure collected data is classified and categorized according to its sensitivity, and that collection methods ensure data accuracy.
Data location
Securing collected data involves considering physical security, implementing appropriate data encryption, ensuring data availability throughout its lifecycle, and ensuring compliance with laws and regulations based on the data's sovereignty and storage location.
Data maintenance
Data maintenance, which involves managing data through its lifecycle, is the process of ensuring confidentiality (e.g., using access controls and monitoring), availability (e.g., ensuring proper and regular backups), and integrity (e.g., identification of inaccurate data, and providing least privilege).
Data retention
Data retention refers to the length of time data is kept and the security implications of retention. Policies should address the business, legal, and compliance requirements for data retention. Retention requirements apply to sensitive data, the media on which it’s stored, systems that process the data, and personnel who have access to the data.
The rule of thumb is to retain data only as long as it’s required and destroy it when it is no longer needed. Factors such as compliance and legal requirements, auditing, and reporting influence retention policies.
Data remanence
Data remanence refers to data remaining on media even after formatting or deletion attempts. Data remanence poses a risk of data leakage or exfiltration when using forensic techniques. It’s essential to use suitable data destruction methods based on the sensitivity of the data.
Data destruction
Once data has reached the end of its useful lifecycle, it should be disposed of in a secure manner, according to its classification. Highly confidential or top secret data will have different disposal requirements compared to public or unclassified data. The organization’s security policy should specify the acceptable data destruction method based on classification.
Secure destruction methods:
Shredding: material or media is physically destroyed by cutting it into strips or pieces.
Crypto-Shredding (cryptographic erasure): encrypts data using an appropriate algorithm, using a strong key. The key is then destroyed.
Incineration/Melting: destroying materials by burning or applying high heat and liquifying.
Disintegration: materials are broken down into very small pieces or particles.
Pulverizing: materials are crushed into a different, unusable form.
Degaussing: using a strong magnet on a metallic storage device to make data unrecoverable.
Insecure methods:
Clearing: overwriting the storage medium with a pattern. This method potentially allows the data to be recovered using forensic methods.
Erasing: deleting or erasing files may leave data remnants that can be recovered using forensic methods.
Purging: a more vigorous version of clearing, usually referring to multiple clearing passes. Purging aims to make data unrecoverable even with laboratory techniques, while clearing only protects against standard software recovery. Purging doesn’t guarantee that data cannot be recovered using forensic methods.
2.5 Ensure appropriate asset retention (e.g., End of Life (EOL), End of Support)
Applying asset lifecycle management, particularly regarding asset retention, including End of Life (EOL) and End of Support (EOS), is essential for understanding the Asset Security domain and is also highly relevant to real-world risk and compliance management.
End of Life (EOL): refers to the point at which an asset (hardware, software, system, or data) is no longer actively sold or maintained by the vendor.
May still be supported for a while, although often there are no further product updates, enhancements, or sales.
Often signals the beginning of planned retirement, and the need to plan for replacement, migration, or decommissioning.
End of Support (EOS): means the vendor no longer provides updates, patches, or security support for the product.
No bug fixes, no security patches.
Product becomes inherently vulnerable to known and emerging threats.
Note: Continuing to use EOS assets = unacceptable risk without mitigation.
2.6 Determine data security controls and compliance requirements
Determining appropriate security controls and ensuring compliance with laws and regulations are important aspects of data security.
Data states (e.g., in use, in transit, at rest)
Understanding the three data states is crucial for both the Asset Security and Communication and Network Security domains of the CISSP Common Body of Knowledge (CBK). Each state represents a distinct phase of data handling and requires separate security controls.
Data at Rest: Data that is stored on a physical or digital medium, not actively moving through networks or being processed. This includes:
Hard drives
Databases
Backups
Cloud storage
USB drives
Protection methods include full-disk, database, or file-level encryption, often using AES (Advanced Encryption Standard), or tokenization.
Perspective: The greatest threat to data at rest is unauthorized access or physical theft.
Data in Transit: AKA data in motion, refers to data that is moving between locations, usually data on the network, or between systems. This includes:
Email
File transfers
API calls
Web/cloud traffic
Protection methods include encryption via TLS (Transport Layer Security) for HTTPS, email, VPNs, IPsec for secure IP-level communication, or SSH for secure access and management of remote systems.
Perspective: The main risks are eavesdropping, man-in-the-middle (MitM) attacks, and data tampering.
Data in Use: Data that is actively being processed by applications or systems in memory or CPU. Examples include:
Data in RAM
Temporarily cached data
Open files being edited
Database queries being processed
Protection methods include memory protection (via process and memory isolation), access control and least privilege (preventing unauthorized users or processes from accessing data), data masking or tokenization (limiting exposure during processing), and endpoint protection (anti-malware, EDR tools).
Perspective: Data in use is the most difficult to protect because it usually must be in plaintext while being processed.
Scoping and tailoring
Scoping and tailoring are essential concepts and ongoing processes that enable an organization to apply security controls customized to its specific needs and requirements.
Scoping: the process of determining the boundaries and assets to which a security control will apply. Includes reviewing a security framework, standard, or set of controls and selecting only those that apply to the specific system, environment, or organization.
Tailoring: the process of customizing selected security controls to better align with the organization’s mission, risk tolerance, and operational environment.
Scoping and tailoring are necessary because not all controls apply equally to all environments, due to factors such as regulatory alignment, risk-based customization, and cost effectiveness.
Standards selection
Organizations must identify and select standards and frameworks that are applicable to their specific needs and requirements. Standards selection is the process by which organizations plan, choose, and document technologies or architectures for implementation.
Security standards and frameworks could include ISO 27001 (Information Security Standard), ISO 42001 (Artificial Intelligence Management System), NIST Cybersecurity Framework (CSF), and PCI DSS.
Applicable industry regulations and organizational needs help define the requirements for selecting frameworks and standards. Scoping the applicable requirement boundaries and tailoring the security control baseline help an organization determine what is necessary to protect systems and data.
Data protection methods (e.g., Digital Rights Management (DRM), Data Loss Prevention (DLP), Cloud Access Security Broker (CASB))
Digital Rights Management (DRM): methods used to protect copyrighted materials, with the goal of preventing the unauthorized use, modification, and distribution of copyrighted works.
Data Loss Prevention (DLP): a security technology and strategy used to detect, monitor, and prevent the unauthorized transmission, access, or disclosure of sensitive data—whether the data is in use, in transit, or at rest.
Three types of DLP to familiarize yourself with for the exam:
Endpoint DLP: monitors and protects data on endpoints (end-user devices such as laptops, desktops, mobile devices) while it is being accessed or modified, including the use of removable media.
Cloud DLP: monitors and protects data within cloud environments like SaaS applications and storage services.
Network DLP: monitors and protects data as it moves across the network, including email, web traffic, file transfers, and other outbound communications.
Cloud Access Security Broker (CASB): a security policy enforcement point positioned between cloud service users and cloud applications that monitors, manages, and enforces an organization’s security, compliance, and governance policies for cloud usage. The four cornerstones of CASBs are visibility, data security, threat detection, and compliance.
CASB acts as a gatekeeper between the enterprise and cloud service providers (CSPs), providing visibility, control, and protection over data and user activity in cloud environments. It ensures compliance with privacy regulations, protects against threats, and provides metrics on cloud application usage.
If you’re on the CISSP journey, keep studying and connecting the dots, and let me know if you have any questions about this domain.
