
Understanding CISSP Domain 3: Security Architecture and Engineering - Part 1

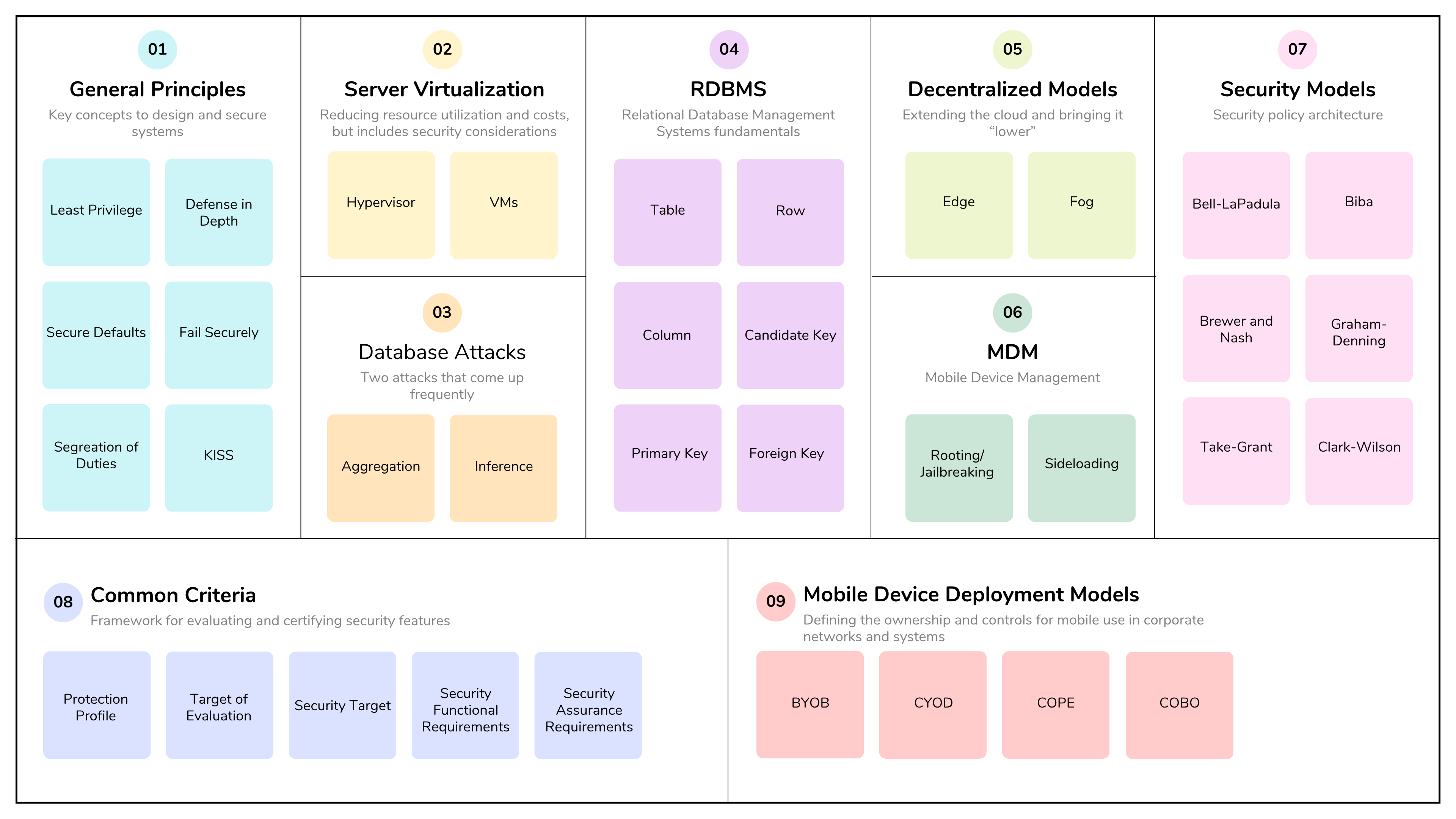
Domain 3 of the CISSP, Security Architecture and Engineering, covers the principles, concepts, and standards used to design, implement, secure, and monitor systems, applications, and networks. This is an important domain because it covers 13% of the exam and, together with Domain 1, provides the foundation for the Common Body of Knowledge (CBK).
In Part 1, we will cover objectives 3.1 through 3.5. Let’s dive into the domain and cover the material by following the ISC2 exam outline.
3.1 - Research, implement and manage engineering processes using secure design principles
The key elements of this objective are researching secure design principles, implementing them into the engineering process, and managing that process throughout the entire lifecycle of a system. This involves integrating security from the start rather than adding it later, which requires understanding secure design principles, using security models, and applying them to systems architecture, design, and development.
Threat modeling
Threat modeling is a security process where potential threats are identified, categorized, and analyzed. It can be performed as a proactive measure during design and development or as a reactive measure once a product has been deployed. Generally, using threat modeling proactively will reduce the cost and complexity of securing a system, providing a better, more integrated, and safer product or solution. Bolt-on security is nearly always inferior to security included from the ground up.
Remember that for the exam, you should know the four primary threat modeling methods (DREAD, OCTAVE, STRIDE, and Trike).
Least privilege
Least privilege means that subjects are granted only the privileges necessary to perform assigned work tasks and no more. The concept should be applied to data, software, and system design to reduce the surface, scope, and impact of any attack.
Defense in depth
Defense in depth means using layered security controls (physical, logical, and administrative) in a series to provide data and asset protection. The logic behind this concept is that if one layer fails, another layer will prevent an attack.
Secure defaults
Secure defaults refer to the practice of configuring systems, applications, and devices with the most secure settings enabled by default, minimizing risk without requiring user intervention.
Why Secure Defaults Are Important:
Reduces risk out of the box – prevents common vulnerabilities caused by weak or open configurations (e.g., default passwords, open ports).
Protects untrained users – ensures baseline security even if users don’t change settings.
Supports defense-in-depth – acts as a foundational control that complements other security measures.
Minimizes human error – fewer misconfigurations from the start.
Fail securely
Fail securely means that if a system, asset, or process fails, it shouldn’t reveal sensitive information or be less secure than during normal operation. Failing securely could involve reverting to defaults. Another way to say this is that a component should fail in a state that denies access rather than granting access. In the case of a network, if a component failed and denied access, traffic would be disrupted. This is also referred to as “fail closed”.
Fail open means that if a system or component fails, everything is allowed to pass through the system. This is appropriate for an availability-critical system or a component related to human safety (such as a fire exit door).
Segregation of Duties (SoD)
Separation of duties (SoD) ensures that no single person has total control over a critical function or system. SoD is a process designed to minimize opportunities for data misuse or environmental damage and help prevent fraud. The usual example is the operation of a movie theater where one person sells tickets while another collects tickets and restricts access to non-ticket holders.
Keep it simple and small
“Keep it simple and small” is a security design principle that means designing systems and components to be as simple and minimal as possible. The idea is to reduce complexity to lower the chance of errors, vulnerabilities, and misconfigurations.
Zero trust or trust but verify
Zero Trust is a security model that assumes no user, device, or system is inherently trusted, even inside the network. It enforces continuous verification, least privilege access, and strict access controls for every request.
🧠 Core idea: “Never trust, always verify.”
Trust but Verify is a traditional security approach that assumes users or systems are generally trustworthy, but includes periodic checks or audits to confirm that trust hasn’t been violated.
🧠 Core idea: “Assume trust, but check occasionally.”
Organizations need to take a zero-trust approach to security. The principle of "trust but verify” is no longer sufficient to secure users, data, workloads, systems, or networks in today’s environment.
Privacy by design
Privacy by design (PbD) is the principle of embedding privacy and data protection controls into systems, processes, and technologies from the start, rather than adding them on later. PbD supports data that is collected minimally, used transparently, and protected by default.
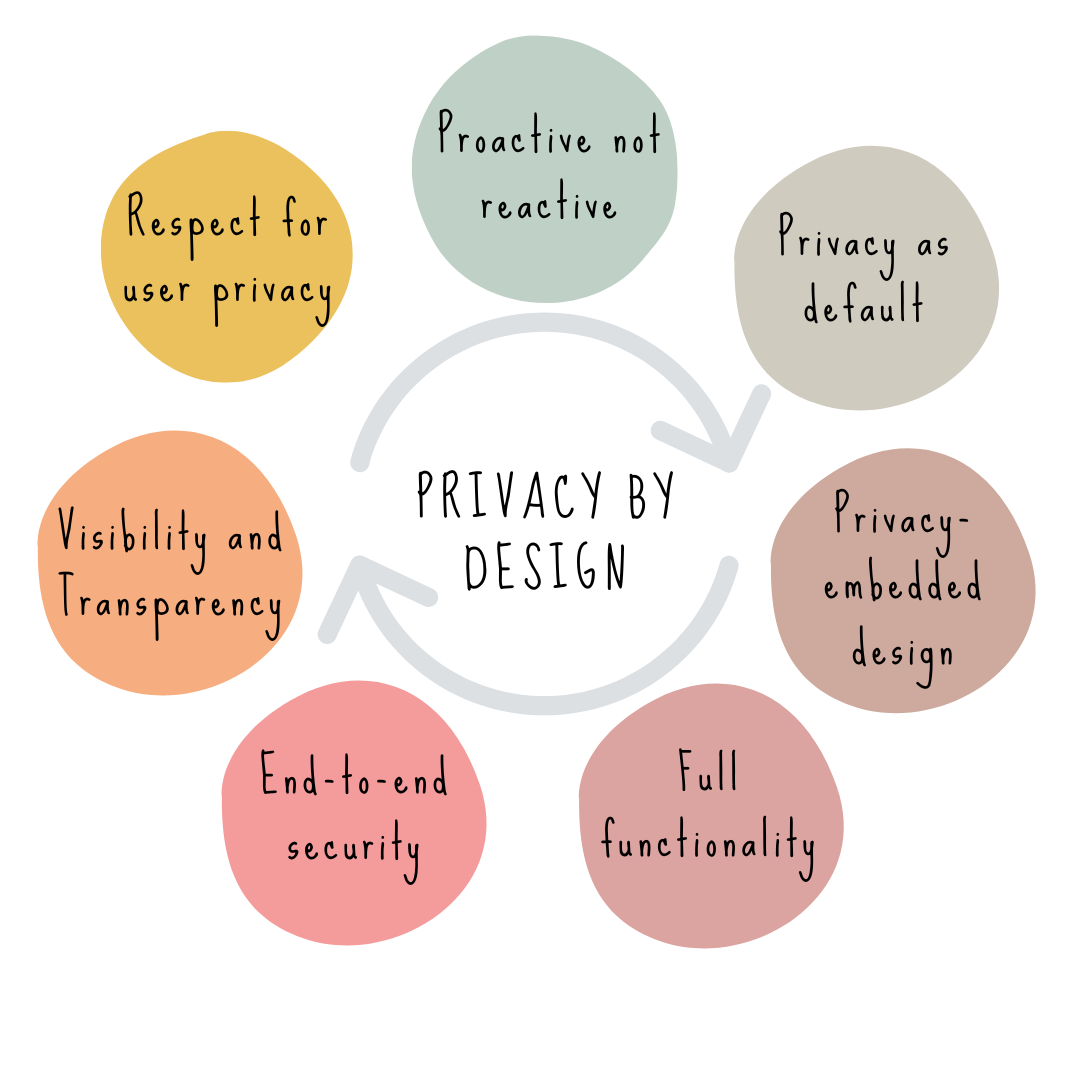
There are 7 recognized principles to achieve privacy by design:
Proactive response: proactive, preventative rather than reactive response.
Default setting: make private by default (e.g., social media app shouldn’t share user data by default).
Embedded: build privacy in or embed it in the design, instead of bolting it on later.
Full functionality, positive-sum: achieve both security and privacy, not just one or the other.
Full lifecycle data protection: privacy should be achieved before, during, and after a transaction.
Visibility, transparency, and openness: publish the requirements and goals, audit them, and publish the findings.
Respect, user-centric: involve end users, provide the right amount of information for them to make informed decisions about their data.
Shared responsibility
Shared responsibility is the security design principle that organizations and people do not operate in isolation. Shared responsibility also refers to the division of security responsibilities between a cloud service provider (CSP) or managed service providers (MSPs) and the customer (organization).
Standard CSP responsibilities are defined by the shared responsibility model, which clarifies that the provider secures the cloud itself, while the customer is responsible for security in the cloud. The exact division of duties varies significantly depending on the specific cloud service model being used—Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), or Software-as-a-Service (SaaS).
Regardless of the cloud model, CSPs are responsible for the following:
Physical security: Protecting the data centers and physical hardware that host cloud infrastructure. This includes controls like restricted access, video surveillance, and environmental safeguards.
Core infrastructure: Securing the foundational components of their service, such as the underlying hardware, networks, virtualization layers, and storage.
Availability and reliability: Ensuring the resilience and uptime of cloud services to meet the performance and availability levels guaranteed in their Service Level Agreements (SLAs).
Compliance validation: Attaining and maintaining industry certifications (e.g., SOC 2, ISO 27001) that demonstrate their compliance with security and privacy standards. They provide audit reports to customers for verification.
General customer security responsibilities under the shared responsibility model include securing everything in the cloud. While specific tasks shift depending on the service model (IaaS, PaaS, or SaaS), the customer is ultimately accountable for the following responsibilities:
Data protection
Identity and access management (IAM)
System and application-level security
Security configurations
The CSP handles the security of the cloud, while the customer is responsible for security in the cloud, especially things like data, identity, and access, and configuration.
Secure access service edge
Secure Access Service Edge (SASE) is a cloud-native architecture that combines networking and security services into a unified, globally distributed platform to securely connect users, devices, and applications — regardless of location.
Coined by Gartner, SASE (pronounced “sassy”) brings together wide-area networking (WAN) and network security functions into a single cloud-delivered service model.
SASE components include:
Firewall services
Secure Web Gateway (SWG)
Cloud Access Security Broker (CASB)
Data Loss Prevention (DLP)
SD-WAN
🧠 Tip: SASE aligns with Zero Trust principles, shifts security closer to the user, and supports cloud-first, remote-friendly architectures — a key evolution in modern security design.
3.2 - Understand the fundamental concepts of security models (e.g., Biba, Star Model, Bell-LaPadula)
Security models are important because they represent the architecture of how security policies are implemented to control access. They help enforce confidentiality, integrity, or availability by establishing broad guidelines and rules, structures, and logic for how subjects (users, processes) can interact with objects (files, databases, systems).
Understanding the different types of security models — beyond just the famous ones like Bell-LaPadula — means recognizing the underlying frameworks used to enforce security policies in systems. These models help designers and analysts reason formally about how access control, confidentiality, integrity, and trust are implemented.
State Machine Model: a system that is always in a defined “secure” state, and any transition between states must preserve that security.
Characteristics:
Based on states, transitions, and inputs
The system moves from one secure state to another via authorized actions
Widely used as the foundation for many other models (like Bell-LaPadula and Biba)
Example:
Trusted Computer System Evaluation Criteria (TCSEC) relies on this concept.
Information Flow Model: focuses on how information moves through a system and ensures it does not flow in a way that violates confidentiality or integrity policies.
Characteristics:
Tracks the flow of data between subjects and objects
Prevents improper disclosure or modification
Can be static (design-time) or dynamic (runtime)
Example:
Used in multilevel security systems to prevent leakage across classification boundaries.
Bell-LaPadula enforces no information flow from high to low.
Lattice-Based Model: use a mathematical lattice structure to define access levels and control flows of information between them.
Characteristics:
Objects and subjects are assigned security labels (e.g., Confidential, Secret, Top Secret)
Access is allowed if the subject’s clearance dominates the object’s classification
Provides granular control over data access
Example:
Bell-LaPadula and Biba models are lattice-based in how they handle classification and integrity levels.
Access Control Matrix Model: uses a matrix to define the rights (read, write, execute) that each subject has over each object.
Characteristics:
Simple and intuitive representation of permissions
Often implemented using Access Control Lists (ACLs) or Capability Tables
Scales poorly for large systems unless optimized
Example:
Foundations for Discretionary Access Control (DAC) and Mandatory Access Control (MAC) systems.
Non-Interference Model: A Non-Interference Security Model ensures that actions taken at a higher security level do not influence or interfere with the behavior at a lower security level.
Characteristics
Strict isolation of data flows ensures actions by users at high security levels don’t interfere or leak into lower security levels
Focus is on confidentiality
Example:
A low-level user should not be able to detect any changes in system behavior (like CPU usage, response time, or log file size) that could reveal the presence of the high-level process.
Models grouped by focus:
Confidentiality:
Bell-LaPadula
Brewer and Nash
Graham-Denning
Take-Grant
Information Flow
Non-Interference
Integrity:
Biba
Clark-Wilson
Confidentiality + Integrity
State Machine
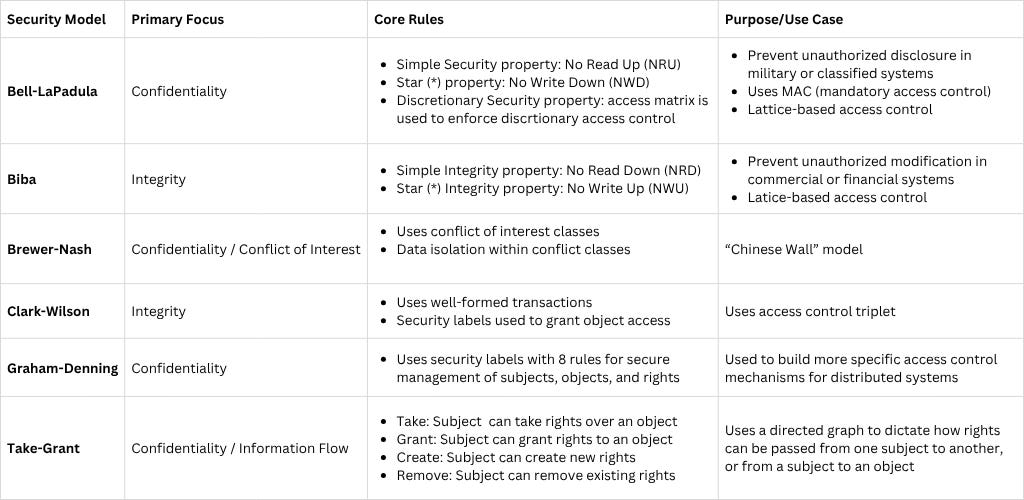
Bell-LaPadula Model (Confidentiality): Designed to protect confidentiality in multilevel security systems, especially military.
Rules:
No Read Up (Simple Security Rule)
No Write Down (*-Property)
Tip: Think of Bell-LaPadula as “don’t leak secrets.”
Biba Model (Integrity): Ensures data integrity by preventing unauthorized modification.
Rules:
No Write Up
No Read Down
Brew and Nash Model (AKA Chinese Wall): Developed to prevent conflicts of interest.
Characteristics:
Access decisions change dynamically based on a user’s past access history
Prevents users from accessing conflicting datasets
Clark-Wilson Model (Integrity): Integrity model designed for commercial environments, based on well-formed transactions and separation of duties.
Characteristics:
Based on the “access control triplet” of subject, object, and access rights.
Uses security labels to grant access to objects.
Constrained Data Items (CDIs): data whose integrity is protected by the security model.
Unconstrained Data Items (UDIs): data not controled by the model.
Integrity Verification Procedures (IVPs): a way to audit data items and confirm integrity.
Transformation Procedures (TPs): only operations the subject is allowed to perform on a CDI.
Graham-Denning Model (Confidentiality): Information flow model that defines secure creation, deletion, and manipulation of subjects, objects, and access rights.
Characteristics:
Eight rules:
Securely create an object.
Securely create a subject.
Securely delete an object.
Securely delete a subject.
Securely provide the read access right.
Securely provide the grant access right.
Securely provide the delete access right.
Securely provide the transfer access right.
Take-Grant Model (Confidentiality): is an information flow and access control model that describes how rights (permissions) can be transferred between subjects (users, processes) and objects (files, resources) in a computer system.
Characteristics:
Uses a directed graph to dictate how rights can be passed from one subject to another.
Four rules:
Take rule: allows a subject to take rights over an object
Grant rule: allows a subject to grant rights to an object
Create rule: allows a subject to create new rights
Remove rule: allows a subject to remove rights it has
3.3 - Select controls based upon systems security requirements
Selecting the right controls is a deliberate process tied to risk management, system categorization, and security architecture. A structured approach helps ensure controls are both effective and aligned with business goals. The following framework provides a repeatable methodology for making informed decisions on security controls.
Identify security requirements: the first step is to fully understand what needs to be protected, and why. Determine system classification, analyze legal and regulatory mandates, establish business-related security objectives, and conduct risk assessment.
Evaluation control options: After identifying the requirements, evaluate potential controls using a risk-based and comprehensive approach. Select a security control framework (e.g. NIST SP 800-53, ISO 27001/2, COBIT), consider appropriate control types (preventative, detective, corrective, deterrent, or compensating), assess control capabilities, and prioritize a defense-in-depth strategy.
Match controls to requirements: map controls to requirements, tailor controls for the environment, consider cost-benefit analysis, involve stakeholders, document decisions, and authorize controls.
Monitor and review: establish continuous monitoring plan, review and update controls.
Be familiar with the Common Criteria (CC) for Information Technology Security Evaluation. The Common Criteria is an international standard for computer security certification, with the primary purpose of providing a framework for evaluating and certifying the security features and capabilities of IT systems and product.
Based on ISO/IEC 15408, CC is a subjective security function evaluation tool that uses protection profiles (PPs), security targets (STs), and assigns an Evaluation Assurance level (EAL).
The key purposes of the Common Criteria (CC) are to provide a standardized, internationally recognized framework for evaluating the security of information technology (IT) products, and to assure customers that these products meet specific security requirements.
Some associated concepts you should be familiar with:
Protection Profile (PP): a document outlining the security needs or customer requirements for a type or category of security products.
Target of Evaluation (TOE): the system or product that is being evaluated.
Security Targets (ST): describes, from the vendor’s perspective, each of the security capabilities or properties of a specific product or system, and how they match up with capabilities outlined in the Protection Profile.
Security Functional Requirements (SFR): specify the security functions or features a product must have.
Security Assurance Requirements (SAR): specify how the product is developed, implemented, and maintained.
An EAL is a numerical rating used to assess the rigor of an evaluation, with a scale from EAL1 (cheap and easy) to EAL7 (expensive and complex). These levels represent increasing levels of security assurance:
- EAL1: functionally tested: minimal security focus, suitable for products with low-security needs.
- EAL2: structurally tested: basic security considerations are included.
- EAL3: methodically tested and checked: the product is methodically tested and checked, with the developer providing more insight into the design and development process.
- EAL4: methodically designed, tested, and reviewed: combines methodical design and testing with a thorough review of the development and security mechanisms.
- EAL5: semi-formally designed and tested: involves formal techniques in the design and testing, making it suitable for high-security applications.
- EAL6: semi-formally verified, designed, and tested: a higher level of assurance suitable for high-risk situations where the value of the protected assets justifies the additional cost.
- EAL7: formally verified, designed, and tested: requires formal verification of the entire design and implementation, making it suitable for extremely high-risk environments where the highest level of security is critical.
3.4 - Understand security capabilities of Information Systems (IS) (e.g., memory protection, Trusted Platform Module (TPM), encryption/decryption)
Capabilities that are part of or inherent in information systems that you should be familiar with include:
Trusted Platform Module
Trusted Platform Module (TPM) is a hardware-based security chip embedded in a computer or device that provides secure cryptographic functions — such as key generation, secure storage, device authentication, and system integrity verification. They can also be used for implementing full disk encryption for Windows and Linux systems.
Reference Monitor Concept
The Reference Monitor Concept (RMC) is a theoretical security model that defines a mechanism to consistently check and control every access attempt by a subject (like a user or process) to an object (like a file or program). Its essential requirements are that the mechanism must be non by-passable, always invoked, tamper-proof, and it must be evaluable to ensure correct operation.
The Reference Monitor Concept is defined by a set of four properties, often remembered by the acronym NEAT:
Non by-passable/Completeness: The mechanism must be positioned so that an attacker cannot get around it to access resources without authorization.
Evaluable/Verifiability: The mechanism’s correctness must be verifiable through analysis and testing, ensuring the security policy is correctly enforced.
Always invoked: The mechanism must be activated for every access attempt, ensuring no requests are missed.
Tamper-proof/Isolation: The mechanism itself must be protected from being altered or disabled by an attacker.
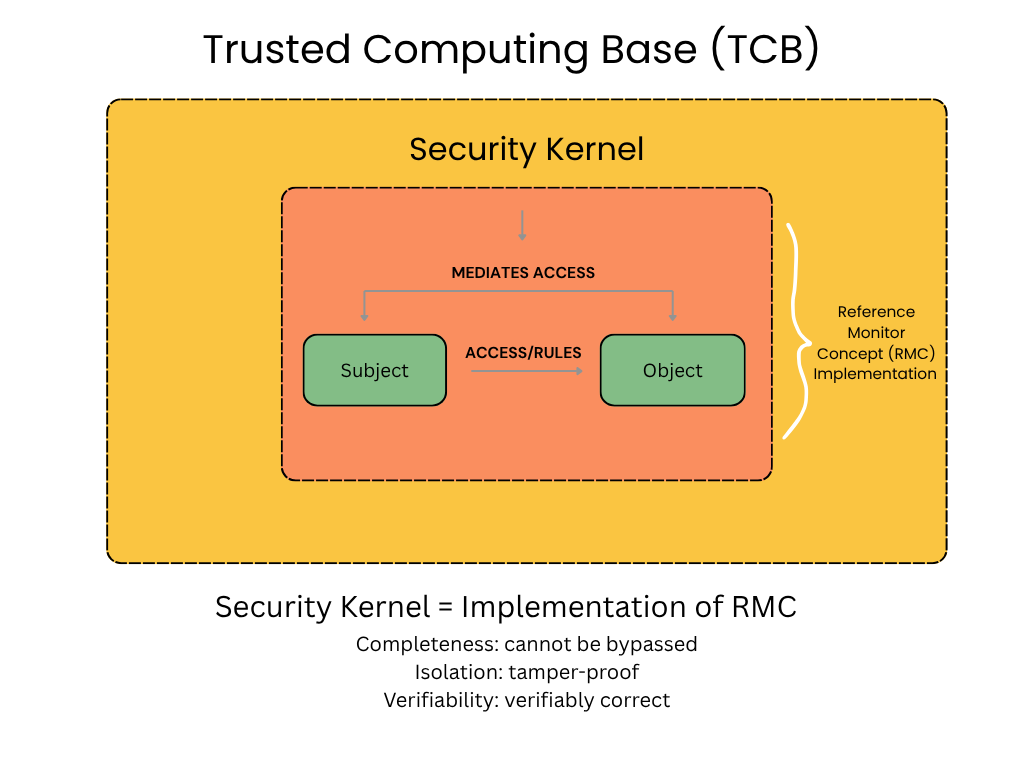
The Security Kernel is simply an implementation of the reference monitor concept, acting like a gatekeeper for a request to a system for resource access.
Remember that a subject is an active entity like a user, process, application, system or even an organization that initiates an access request. An object is something like applications, files, or systems that is the passive target of the access request.
A Trusted Computing Base (TCB) is the sum total of all hardware, firmware, and software within a computer system that is responsible for enforcing its security policy. It includes components like the operating system kernel, secure boot firmware, and security-critical applications, as well as hardware like a Trusted Platform Module (TPM). The TCB is considered the foundation of a system’s security, and any vulnerability in one of its components can jeopardize the entire system.
Abstraction in computer science is the process of simplifying complex systems by focusing on essential features while hiding unnecessary details. It is important because it reduces complexity, makes code more readable and maintainable, and allows developers to manage large and intricate programs more effectively.
Virtualization carries the concept of abstraction further, because virtualization is the process of creating a virtual version of something that abstracts it from the true underlying hardware or software. For instance, a virtualized system uses software to create virtual versions of computing resources, like servers, operating systems, storage, and networks, from a single physical machine. This process allows multiple independent virtual machines (VMs) to run on one physical host, managed by a hypervisor. Benefits include increased efficiency, lower costs, better scalability, and the ability to run different operating systems side-by-side.
Processors
A central processing unit (CPU) is an integrated circuit that is the brain of a computer. It processes all instructions (fetching instructions and data, decoding instructions, executing instructions, and storing results) from computer programs and performs calculations, logic, and input/output operations.
Processor Modes
The system kernel is the core of an operating system, with complete control over everything in the system. It has low-level control over all of the operational pieces of the operating system. In essence, it has access to everything.
User and kernel processor modes are two distinct execution states with different privilege levels:
User mode: a restricted mode for applications, preventing them from directly accessing hardware or sensitive memory to ensure system stability and security.
Kernel mode: a privileged mode for the operating system’s core components, which allows them to have full access to the hardware and manage system resources. Kernel mode is also known as privileged or supervisory mode.
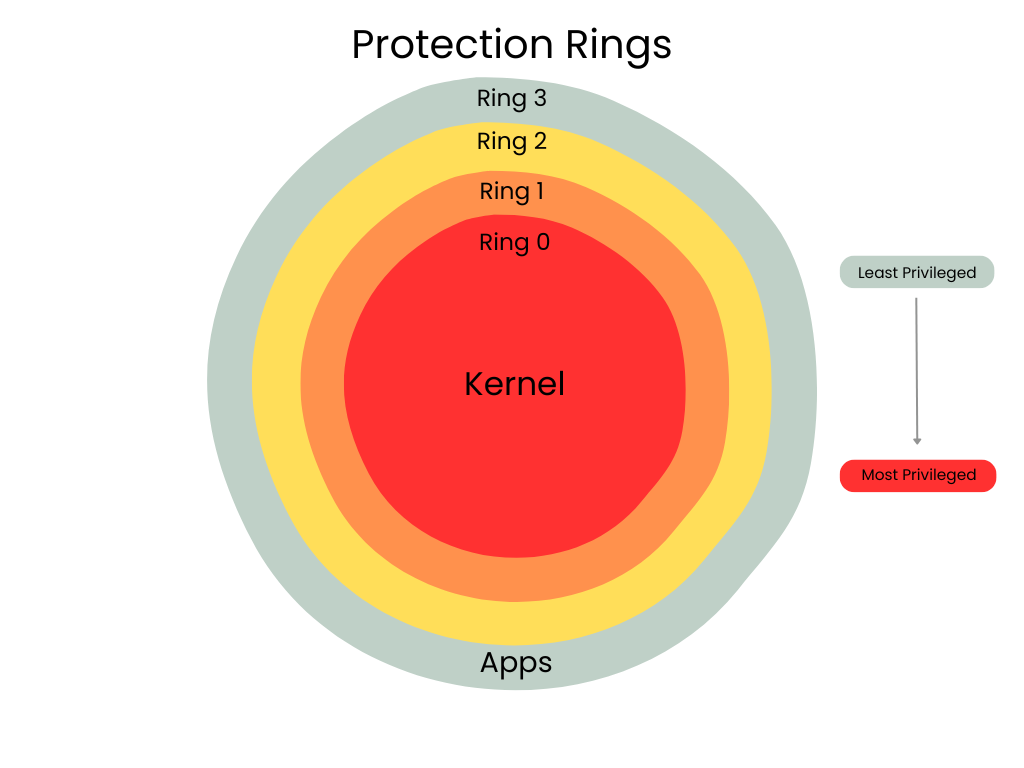
Protection Rings
Protection rings are a security mechanism and form of layering used by most operating systems to provide protection for privilege levels and enforce access controls. There are four protection rings, or levels, numbered from 0 to 3, designating the most trusted and secure (ring 0, the kernel mode) to least trusted and secure (ring 3, the user mode).
Ring 0: kernel mode is the most privileged with unrestricted access to system hardware and resources. Its purpose is to protect the core of the operating system from less trusted code or levels.
Ring 1 and 2: are intermediate privilege levels, although these rings are not widely used in modern operating systems. Theoretically these rings could be used for device drivers and system services.
Ring 3: user mode is the least privileged level, where user-level applications, such as web browsers or word processors, run. Its purpose is to restrict applications from accessing hardware or modifying critical system data, which prevents them from crashing the system or acting maliciously.
Memory Types
Memory is categorized as primary (RAM and ROM) and secondary storage. Random Access Memory (RAM) is volatile (requires power to retain data) used for active tasks, with types that include SRAM and DRAM. Read Only Memory (ROM) is non-volatile (keeps data even after power is turned off), permanent storage for firmware and boot instructions, with types like MROM, PROM, EPROM, and EEPROM.
PROM (Programmable ROM): Can be written to once.
EPROM (Erasable Programmable ROM): Can be erased allowing reprogramming.
UVEPROM (Ultraviolet EPROM): Can be erased with ultraviolet light and reprogrammed
EEPROM (Electrically Erasable Programmable ROM): Can be erased and rewritten electrically, without removal from the circuit.
MROM (Mask ROM): Factory-programmed and cannot be changed.
Secondary storage is non-volatile and serves as a long-term, lower-cost, and higher-capacity solution compared to primary memory (RAM). It stores operating systems, applications, and user data. Common examples include hard disk drives (HDDs), solid-state drives (SSDs), USB drives, SD cards, and optical discs.
The primary security concerns with secondary storage relates to the need for access controls and encryption to be applied to protect data, and ensure that if removable media is stolen, data is not accessible without the encryption key.
Process Isolation
From a security perspective, process isolation is a critical element of computing, as it prevents objects from interacting with each other and their resources. It is often accomplished using two primary methods: multiplexing or hardware segmentation.
Time division multiplexing (TDM) is a method for multiple processes or tasks to share the same physical resources (such as a CPU) by taking turns and assigning each a specific, recurring time slot. This is a form of multiplexing that enables multitasking and efficient use of resources by allowing the CPU to switch between different tasks in rapid succession, so it appears as if they are running simultaneously. While TDM is commonly used in telecommunications, its underlying principle is also applied in computer science, such as in operating systems to manage and schedule process execution.
Memory segmentation ensures that the memory assigned to one application is only accessible by that application. In general, it is a memory management technique that divides a computer’s memory into logical blocks called segments, each with a specific purpose and access permissions. This method improves memory organization and protection by treating different parts of a program, such as code, data, and stack, as distinct segments.
3.5 - Assess and mitigate the vulnerabilities of security architectures, designs, and solution elements
Client-based systems
Client-based or endpoint systems are devices like laptops, desktops, and mobile phones that can access and process data from servers and cloud services. Some endpoint attack and security considerations include:
Local data storage: Storing sensitive data (data at rest) on the client device without proper encryption makes it vulnerable to unauthorized access if the device is compromised. Controls include full-disk encryption (FDE), trusted platform module (TPM) for FDE and secure boot support, and data loss prevention (DLP).
Phishing and Malware: Users are susceptible to phishing attacks, and clients can be infected by malicious data or programs like viruses, worms, and trojans, which can spread to the network. Controls include anti-malware software, endpoint detection and response (EDR), user security awareness training, and patch management.
Client-side attacks: Attacks like digital skimming and form jacking can compromise user data at the point of interaction in the browser.
Physical: Devices such as keyloggers can intercept input devices and record or capture keystrokes. And devices such as thumb or USB drives can introduce malware, or be used to exfiltrate sensitive data. Use security measures such as electronic locks, security cameras, and security guards to restrict access to sensitive devices and reduce the risk of physical threats.
Mobile Device Management (MDM) is a type of security software and set of processes that organizations use to manage, monitor, and secure mobile devices—such as smartphones, tablets, and laptops—that access corporate resources.
Its basic purpose is to enforce corporate security policies, manage applications, and protect sensitive business data, especially in environments where employees use personal devices for work (e.g. Bring Your Own Device (BYOD) policies).
MDM solutions are crucial for mitigating risks, particularly those that bypass a device’s standard security controls. Three significant security considerations an MDM system helps address are rooting/jailbreaking, sideloading, and the resulting loss of control.
Rooting (for Android devices) and Jailbreaking (for iOS devices) are processes that allow the user to gain privileged control or “root access” over the device’s operating system. This is done to remove vendor or carrier restrictions, install unauthorized software, and deeply customize the device. Security implications include by-passed security, potential malware exposure, and loss of warranty and updates.
Sideloading is the act of installing an application onto a mobile device from an unofficial source, rather than downloading it from the official app store. Security implications include loading unvetted and potentially malicious software, and reducing the barrier to an attacker’s unauthorized access to the device. Customized firmware can also be sideloaded, increasing the probabilities of software vulnerabilities, data loss, and malware infection.
Mobile Device Deployment Policies
Mobile device deployment policies define the ownership, usage, and control models for the mobile devices employees use to access corporate data and systems. The four main policies—BYOD, CYOD, COPE, and COBO—represent a spectrum from maximum employee freedom to maximum organizational control.
Bring Your Own Device (BYOD): Employees use their personally-owned smartphones, tablets, and laptops for work purposes. Security concerns include personal and organizational data co-mingling, limited IT controls, privacy conflicts, data leakage, and issues with security policy enforcement.
Choose Your Own Device (CYOD): Employees select a device from a limited, pre-approved list provided by the company. Ownership may vary, but the device is usually primarily for work. Security concerns include user privacy, licensing enforcement, potential ownership confusion, and privacy issues.
Corporate-Owned, Personally-Enabled (COPE): The company purchases and owns the device but allows employees to use it for personal purposes. Security concerns are similar to BYOD, including data co-mingling, privacy concerns (the company owns the device and can access the employee’s personal data), as well as compliance issues.
Corporate-Owned, Business-Only (COBO): The company owns the device, and its use is strictly limited to work purposes. Personal use is banned. Security and practicality concerns include user resistance, limited flexibility, productivity impact, and high costs.
Unified Endpoint Management (UEM) is a class of software and a set of strategies that allows an organization to manage, monitor, and secure all end-user computing devices from a single, centralized console.
It represents the evolution of older tools like Mobile Device Management (MDM) and Enterprise Mobility Management (EMM) by bringing traditional IT client management (for desktops and laptops) together with mobile management.
The primary goal of UEM is to provide a single “pane of glass” for IT and security teams to oversee and control a diverse array of endpoints, regardless of the operating system or location.
Server-based systems
Server virtualization is a technology that uses a software layer, called a hypervisor, to divide a single physical server (the host) into multiple, isolated virtual servers (called Virtual Machines or VMs).
Each VM operates as an independent computer with its own operating system, applications, and dedicated virtual resources (CPU, memory, storage), all while sharing the physical hardware of the host machine. This greatly improves resource utilization, reduces hardware costs, and increases IT flexibility.
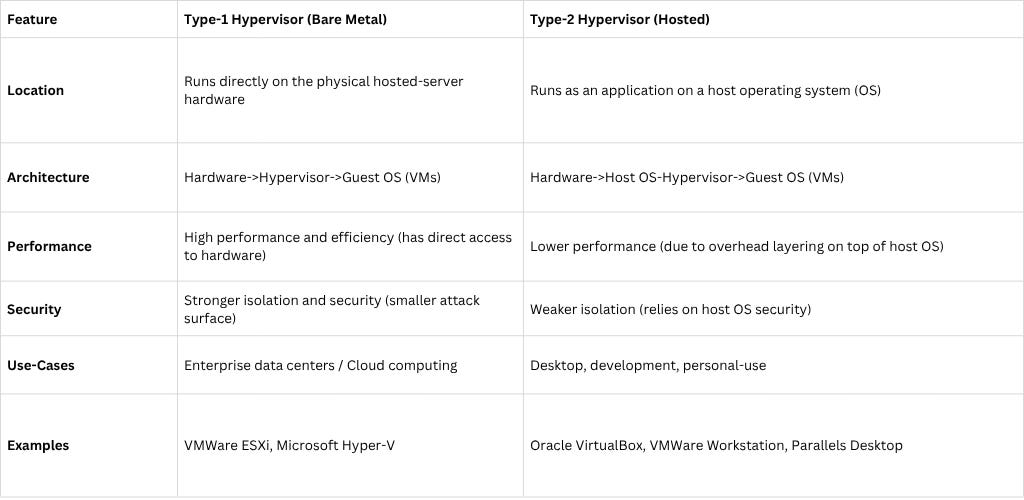
A hypervisor (also known as a Virtual Machine Monitor or VMM) is the software layer that creates and manages the VMs, allocating the host’s physical resources to each one. There are two main types of hypervisors, categorized by where they sit in relation to the hardware identified as Type 1, or Type 2.
A Type 1 hypervisor essentially replaces the host operating system. When you boot the physical server, the Type 1 hypervisor loads directly onto the hardware, giving it absolute control over the server’s resources.
A Type 2 hypervisor is installed as a standard application on a conventional operating system (like Windows, macOS, or Linux). It uses the host OS’s drivers and services to access the underlying hardware.
The primary security concerns with server virtualization revolve around the hypervisor as a single point of failure and the challenges introduced by the shared, complex environment. A compromise at this central level can potentially affect every VM hosted.
Additional security concerns include:
VM Escape: This is the most severe threat. It occurs when an attacker exploits a vulnerability in the hypervisor to “break out” of their isolated VM and gain unauthorized access to the underlying host system or other VMs on that host.
VM sprawl: the uncontrolled proliferation of virtual machines (VMs) that results in inefficient resource use, management complexity, and security risks. It occurs when VMs are created faster than they can be decommissioned, leading to a large number of unmanaged and underutilized virtual servers that consume storage, licensing, and administrative resources.
Shadow VMs: virtual machines used in an organization that are not controlled by the IT function, which can lead to vulnerabilities associated with unmanaged, and unpatched systems.
Securing server virtualization requires a layered approach focusing on the hypervisor (the foundation), the VMs, and the virtual network. The key security controls and considerations fall into four main areas: hardening and patching, policy and access control, vulnerability management, and continuous monitoring.
Regularly update and patch the hypervisor and host operating system (if applicable) to mitigate known vulnerabilities (e.g., VM escape flaws). Disable unnecessary services (like SSH, FTP, or web consoles) and close unused ports to reduce the attack surface.
Implement access controls across the hypervisor management platform, and use least privilege, granting users only the permissions required for their specific job role.
Enable comprehensive logging and audit trails for all activities on the hypervisor and management servers. Forward these logs to a Security Information and Event Management (SIEM) system for real-time analysis, alerting on suspicious activity, and forensic investigation.
Virtual Desktop Infrastructure (VDI) is a technology that hosts and manages desktop operating systems (like Windows or Linux) and applications on a centralized server in a data center or the cloud. Instead of using a traditional physical desktop computer, the end-user connects to their virtualized desktop session remotely using a client device (laptop, tablet, thin client, etc.).
The primary security benefit of VDI is data centralization. Since all data resides on the central server and not on the end-user’s device, the risk of data loss or theft from a lost or stolen laptop is significantly reduced.
While VDI offers centralized control, it also consolidates risk, creating unique security challenges:
Hypervisor and endpoint security: the hypervisor controls all virtual desktops on the physical host, so preventing compromise by following the above hypervisor control suggestions is important. It’s also important to ensure endpoints are patched and protected against threats.
Data Loss Prevention (DLP): Even if data is centralized, users can still intentionally or accidentally copy sensitive files from the VDI session to their unsecured local device so using DLP is a necessary.
Network Security: Since all virtual desktops are on the same network and managed centrally, malware or ransomware can potentially spread rapidly between virtual machines or laterally to the core infrastructure if network segmentation or security is weak.
Virtual Mobile Infrastructure (VMI) is a computing model that hosts mobile operating systems (OS) and applications on a centralized server—either in a data center or the cloud—and streams the user interface to the end-user’s physical mobile device.
It is essentially the mobile counterpart to VDI, but specifically optimized for the constraints of mobile networks and the user experience of a smartphone or tablet.
System Hardening
System hardening is a collection of tools, techniques, and best practices used to reduce security vulnerabilities across an entire technology environment.
The core goal of system hardening is to reduce the system’s “attack surface”—the sum of all the different points where an unauthorized user could try to enter or compromise a system—thereby making it significantly more difficult for attackers to gain a foothold.
It is a methodical, continuous process of auditing, identifying, and eliminating potential security risks in configurations and settings.
Hardening applies to every component of IT infrastructure, including servers, operating systems, networks, applications, and databases. Common practices include:

Database systems
Database systems organized collections of information that is stored for efficient retrieval, management, and updating.
Relational Database Management Systems (RDBMS) are the most common type. Data is organized into tables with rows and columns, and these tables are related to each other via keys. They typically use SQL (Structured Query Language).
NoSQL Databases (Non-Relational) are designed for flexibility and handling large volumes of unstructured or semi-structured data (like documents or graph relationships). Types include Document, Key-Value, and Graph databases.
Database Architecture
A database system’s architecture outlines the structural design and components that manage and maintain the data effectively. It is fundamentally divided into how users view the data (the logical structure) and how the data is physically stored and accessed by the system.
Here is an overview of the core architectural models and related concepts.
A Table (also called a relation) is the basic structure used to store data in a relational database. It organizes data into a two-dimensional grid consisting of named columns and rows. Each table represents a distinct entity type (e.g., Customers, Products, Orders).
A Row (also called a tuple or record) represents a single, complete, and implicit structured data item in a table. In simpler terms, each row is a unique instance of the entity the table represents (e.g., one specific customer, one specific product).
A Column (also called an attribute or field) represents a specific property or characteristic of the entity defined by the table. All the data values in a column are of the same data type and represent the same attribute for every row (e.g., Customer Name, Product Price).
Keys are crucial for uniquely identifying rows and for establishing logical relationships between tables, which maintains data integrity.
A Candidate Key is an attribute, or a minimal set of attributes, that can uniquely identify every row in a table.
The Primary Key is the candidate key that the database designer chooses to be the principal unique identifier for the table. It is the most important key for accessing and referencing data. The primary key must contain unique values (no duplicates), and a table can have only one Primary Key.
A Foreign Key is an attribute, or a set of attributes, in one table (the referencing or ‘child’ table) that refers to the primary key of another table (the referenced or ‘parent’ table). Its primary purpose is to establish a link or relationship between two tables, thereby enforcing referential integrity.
Referencial integrity ensures that values in the foreign key column of the child table must already exist in the primary key column of the parent table, preventing invalid data references (e.g., an order cannot be created for a customer who doesn’t exist).
The ACID model is a set of properties that guarantee the validity of database transactions. It ensures that the data remains accurate and consistent even after concurrent operations or system failures. ACID is a cornerstone of reliability for relational database management systems (RDBMSs).
Atomicity means that a transaction must be treated as a single, indivisible unit of work. It is an “all or nothing” principle.
Consistency ensures that a transaction takes the database from one valid state to another valid state.
Isolation ensures that the each concurrent transaction doesn’t interfere with others, and is executed in sequence (one after the other).
Durability guarantees that once a transaction has been successfully committed, its changes are permanent and will survive any subsequent system failure.
Two database attacks that you should understand:
Aggregation attack: an aggregation attack is based on math. For instance, an attacker combining multiple pieces of non-sensitive information to figure out or derive sensitive information.
Inference: is an attack based on human deduction and logical reasoning. It involves combining several pieces of non-sensitive data to gain access to that which should be classified at a higher level. Inference makes use of the human mind’s deductive capacity rather than the raw mathematical ability of database platforms.
Defenses against aggregation and inference attacks focus on limiting the information available to any single query and introducing controlled uncertainty into the data:
Data Masking/Anonymization: Modifying or hiding sensitive attributes in the published data or query results.
Query Restriction/Size Restriction: Imposing rules to prevent queries that are too specific or that return too many records.
Foundational security: measures that limit an attacker’s ability to gather the necessary non-sensitive data in the first place such as least privilege and role-based access control (RBAC).
Cryptographic systems
The overall goal of a well-implemented cryptographic system is to make compromise too time-consuming and/or expensive. The overall idea is protecting information’s Confidentiality, Integrity, Authentication, and Non-repudiation (often abbreviated as the CIA Triad + Non-repudiation).
Confidentiality: the goal is to make information accessible only to those authorized to have access, keeping it secret from unauthorized.
How Cryptography Helps: achieved primarily through encryption. The data is converted into an unreadable format (ciphertext) using an encryption algorithm and a key, so that even if an unauthorized party intercepts the data, they cannot understand or use it.
Commonly used:
AES (Advanced Encryption Standard)
RSA (Rivest-Shamir-Adleman)
TLS (Transport Layer Security)
Integrity: the goal is to ensure that data has not been altered or tampered with by unauthorized means, either accidentally or maliciously, during transmission or storage.
How Cryptography Helps: This is achieved through Cryptographic Hashing and Message Authentication Codes (MACs), where a unique, fixed-length hash value (or digest) is generated for the data. If even a single bit of the data is changed, the new hash value will be completely different, immediately alerting the recipient to tampering.
Commonly used:
SHA-256 (Secure Hash Algorithm 256-bit)
HMAC (Hash-based Message Authentication Code)
DSA (Digital Signature Algorithm)
Authentication: the goal is to confirm the identity of a user, system, or entity trying to access a resource or communicate with another party.
How Cryptography Helps: This is achieved using Digital Signatures and Challenge-Response protocols. Public-key cryptography ensures that a message or access request truly originates from the claimed sender, as only the genuine owner possesses the secret private key required to produce a valid digital signature.
Commonly used:
PKI (Public Key Infrastructure)
SAML (Security Assertion Markup Language)
Non-Repudiation: the goal is to provide irrefutable proof that a specific action (like sending a message or placing an order) was carried out by a specific entity, preventing that entity from later denying they performed the action.
How Cryptography Helps: relies on Digital Signatures combined with a trusted third party. Since a unique private key is required to create a signature, and only the owner has that key, the resulting signature acts as legal evidence that the owner willingly signed the document or sent the message, and they cannot later repudiate (deny) the transaction.
Commonly used:
DSA (Digital Signature Algorithm)
RSA signatures
Industrial Control Systems (ICS)
Industrial control systems (ICS) are a form of computer-management device that control industrial processes and machines, also known as Operational Technology (OT). OT refers to hardware and software used to monitor and control physical processes, devices, and infrastructure. These systems are often called Industrial Control Systems (ICS) and are critical to sectors like manufacturing, energy, water treatment, and transportation.
ICS use a network of distributed controllers to manage industrial processes such as power plants, water treatment, chemical processing, and associated management systems.
There are several forms of ICS including distributed control systems (DCS), programmable logic controllers (PLC), and supervisory control and data acquisition (SCADA).
The main goal of these systems is to automate and regulate industrial operations. Key examples include:
SCADA (Supervisory Control and Data Acquisition): Large-scale, geographically dispersed control systems that monitor and control facilities or complex systems across vast areas, such as pipelines, power grids, or water distribution networks.
DCS (Distributed Control System): A control system usually found within a single factory or plant. It uses a network of controllers managed by a central supervisory control level to control local processes.
PLC (Programmable Logic Controller): A rugged, industrial computer used to automate specific electromechanical processes, such as controlling machinery, assembly lines, or robotic devices in a factory floor.
RTU (Remote Terminal Unit): A micro-processor-controlled device that interfaces objects in the physical world to a DCS or SCADA system by transmitting telemetry data to the master station and relaying control commands back to the field device.
HMI (Human-Machine Interface): The graphical user interface (like a screen or console) that operators use to monitor and interact with the physical processes and control systems.
OT/ICS environments face unique and severe security concerns compared to traditional IT networks, primarily because compromise can lead to physical damage, environmental harm, or loss of life. Some of the primary concerns are:
Legacy systems and patching: many ICS components have long life cycles (20+ years), run on outdated operating systems, and cannot tolerate frequent patching or reboots, making them vulnerable to known exploits.
Availability over confidentiality: the primary goal of OT is availability (keeping the physical process running). Security measures (like frequent updates or complex authentication) that might cause downtime are often rejected, prioritizing uptime over security.
Lack of built-in security: ICS systems were created for reliability, not necessarily security. ICS networks often use non-standard, proprietary communication protocols (e.g., Modbus, DNP3) that lack built-in security features like encryption or authentication, making them easy to eavesdrop on or manipulate.
Controls and mitigations include:
Network segmentation: separate the OT network from the IT network (and internal OT zones from each other).
Robust change management: strictly control and document all changes, patches, and configurations in the OT environment. Only apply vendor-approved patches after thorough testing in a staging environment.
Physical security: make sure that controls include physical access restrictions to protect components.
Encryption: use secure communications between components if possible.
System hardening: disable unused ports and services on controllers, HMI stations, and servers. Implement whitelisting to ensure that only approved applications and code are allowed to execute.
Cloud-based systems (e.g., Software as a Service (SaaS), Infrastructure as a Service (IaaS), Platform as a Service (PaaS))
Cloud computing is the on-demand delivery of IT resources and applications—such as servers, storage, databases, networking, software, analytics, and intelligence—over the internet (the “cloud”) with pay-as-you-go pricing. Instead of owning and maintaining physical data centers and servers, you access technology services from a cloud provider (like AWS, Azure, or Google Cloud).
The U.S. National Institute of Standards and Technology (NIST) defines five essential characteristics that distinguish cloud computing from traditional hosting or virtualization:
On-Demand Self-Service: Users can provision computing capabilities, such as server time and network storage, automatically without requiring human interaction with each service provider. Users get what they need, when they need it, typically through a web portal or API.
Broad Network Access: The capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous client platforms (e.g., mobile phones, tablets, laptops, workstations).
Resource Pooling: The provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand. The customer generally has no control or knowledge over the exact location of the provided resources.
Rapid Elasticity (Scalability): Capabilities can be elastically provisioned and released, in some cases automatically, to scale rapidly commensurate with demand. To the consumer, the capabilities available for provisioning often appear to be unlimited and can be purchased in any quantity at any time.
Measured Service: Cloud systems automatically control and optimize resource usage by leveraging a metering capability at some level of abstraction appropriate to the type of service (e.g., storage, processing, bandwidth). Resource usage can be monitored, controlled, and reported, providing transparency for both the provider and the consumer (enabling the pay-as-you-go model).
Cloud service models
The three primary service models used in cloud computing are Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). They represent different layers of the computing stack that the cloud provider manages versus what the customer manages.
Infrastructure as a Service (IaaS)
IaaS provides the fundamental computing resources, essentially offering virtualized hardware over the internet.
The customer manages and is responsible for the security of the Operating systems (OS), middleware, runtime, data, and applications.
The CSP manages the datacenter, associated staff and the supporting components such as networking, storage, servers, and virtualization.
Platform as a Service (PaaS)
PaaS provides business applications such as development and deployment environment in the cloud. It gives users everything they need to run, manage, and scale applications without worrying about the underlying infrastructure.
The customer manages only the applications and the data.
The CSP manages configuration and provisioning of the operating systems, middleware, and runtime environment.
Software as a Service (SaaS)
SaaS provides complete, ready-to-use applications to the end-user over the internet.
The customer manages only the usage of the software and, in some cases, user settings and application-specific data.
The CSP manages all aspects of the application stack, from the infrastructure to the application code itself.
Function as a Service (FaaS)
Function as a Service (FaaS) is a serverless computing model where a cloud provider manages all the infrastructure (servers, operating systems, and capacity scaling), allowing users to simply upload and run small, single-purpose blocks of code, known as functions, in response to specific events.
Functions are executed only when triggered by an external event. This could be an HTTP request, a file upload to cloud storage, a new message in a queue, or a database change. The platform automatically and instantaneously scales the execution of the function up (to handle millions of requests) or down (to zero) based on the volume of incoming events.
Cloud deployment models
The cloud deployment models define the ownership, scale, and access of the cloud environment. There are four primary models: Public, Private, Hybrid, and Community clouds.
The Public Cloud model offers computing services over the public internet to any customer who wants to use or purchase them. Offers scalability, low-skill requirements and investment, and pay-as-you-go cost.
The Private Cloud model is exclusive to a single organization. It can be managed by the organization’s own IT department or by a third-party, but the infrastructure and resources are isolated. This model offers the highest level of security and control, often used for sensitive data and regulatory compliance.
The Community Cloud model is shared by several organizations that have common concerns, such as specific security requirements, policy mandates, or compliance considerations (e.g., a consortium of banks, government agencies, or healthcare organizations).
The Hybrid Cloud model is a combination of two or more distinct cloud infrastructures (private, public, or community) that remain unique entities but are bound together by standardized or proprietary technology that enables data and application portability.
Some of the security considerations for cloud computing include:
Shared responsibility: this is the most fundamental consideration. You must know where the CSP’s responsibilities end and yours begin, which changes based on the service model. Security is a collaboration and shared responsibility between an organization and the cloud service provider. In general, the CSP is responsible for the security of the cloud (the physical infrastructure), and the customer is responsible for the security in the cloud (the data, access, and configuration).
Jurisdiction and Data Location: Customers may lose direct control over the physical location of their data. This raises concerns about meeting data residency requirements (e.g., data that must remain in a specific country) and which national laws govern the data (e.g., GDPR, CCPA).
Identity and Access Management (IAM): Cloud resources are managed entirely through web consoles and Application Programming Interfaces (APIs), which are the most exposed control planes. Compromised credentials (including API keys) can grant an attacker complete control.
Cloud Misconfiguration: This remains the top cause of cloud breaches. Simple errors like leaving a cloud storage bucket (e.g., S3) publicly accessible, or firewall ports open, are extremely common.
Distributed systems
A distributed system, or distributed computing environment, is a collection of independent computers (nodes) that are interconnected by a network and appear to their users as a single, coherent system. These nodes cooperate to achieve a common task, process data, or manage shared resources. The internet is a prime example of a distributed system.
Distributed systems inherently face amplified security challenges compared to centralized systems because of their complex, decentralized nature and reliance on network communication.
Communication channel security: data is constantly being sent between nodes over a network, making it vulnerable to eavesdropping (interception) and man-in-the-middle (MITM) attacks if communication channels aren’t properly secured.
Distributed compromise: an attack compromising one node might be used as a base to spread malware or exploit vulnerabilities laterally across the network, escalating the system’s overall compromise.
Access control and logging: maintaining consistent access control, authentication, patching and logging may be challenging in a distributed system.
Internet of Things (IoT)
The Internet of Things (IoT) refers to a network of physical objects (”things”) embedded with sensors, software, and other technologies for the purpose of connecting and exchanging data with systems over the internet. Essentially, it brings almost any physical object into the digital realm, enabling it to collect, send, and act on data.
IoT devices pose unique security challenges due to their constrained processing power, sheer number, and typical deployment outside secure perimeters.
Weak Authentication and Access Control: Many devices ship with default, unchangeable credentials (like “admin/admin”) or lack strong authentication mechanisms entirely, making them easy targets for brute-force attacks or compromise by non-technical users. Mitigations include enforcing unique, complex credentials upon setup, and using MFA for management interfaces if available.
Insecure Ecosystem and Firmware: IoT firmware can include vulnerabilities that attackers can easily exploit. Mitigations include implementing secure over-the-air (OTA) update mechanisms with cryptographic validation, and signed firmware to ensure its integrity.
Constrained memory, storage, and processing power: limited or constrained storage may lead to insufficient logging and poor security implementations of user authentication. Mitigations include implementing efficient or off-device logging mechanisms, and encryption such as ECC (elliptic curve cryptography).
Microservices (e.g., application programming interface (API))
Microservices (often simply called “microservice architecture”) are an architectural style where a single application is structured as a collection of many small, independent services. Each service runs its own process, is developed, deployed, and managed independently, and communicates with other services, usually through lightweight mechanisms like HTTP APIs.
Microservice architectures significantly expand the attack surface compared to traditional monolithic applications, introducing new challenges in communication, identity, and data management:
Increased attack surface and communication security challenges due to the complex architecture and communication path.
Complex identity and access management since every service needs to verify not just the end-user, but also the identity and permissions of the calling service. Managing these complex trust relationships across potentially hundreds of services is challenging.
Since each service is managed independently, security configuration settings (e.g., encryption algorithms, timeout limits) changes can lead to inconsistencies (“drift”) where some services are left unsecured or unpatched.
Containerization
Containerization is a method of packaging an application and all its dependencies (libraries, configuration files, and system tools) together so that it can run quickly and reliably in any computing environment, whether on a developer’s laptop, an on-premises server, or in the cloud.
Unlike a virtual machine (VM), a container does not include a full operating system (OS). Instead, it shares the host system’s OS kernel but runs in isolation, making containers lightweight, fast to start, and highly portable. The most widely known container platform is Docker.
While containers provide efficiency, their shared-kernel model and complex deployment pipelines introduce several unique security challenges:
Runtime and Orchestration Security: in large deployments managed by orchestrators (like Kubernetes), misconfigurations in the orchestration platform (e.g., leaving the API server unsecured) can expose the entire cluster. Also, securing the runtime environment involves isolating processes and monitoring network traffic between containers.
Insecure Container Images and Supply Chain: Container images are often built on top of public, unverified base images (from repositories like Docker Hub). These base images may contain known vulnerabilities, outdated libraries, or even embedded malware. This is a software supply chain risk.
Serverless
Serverless computing is a cloud execution model where the cloud provider dynamically manages the allocation and provisioning of servers, allowing developers to build and run applications without having to manage any of the underlying infrastructure.
Despite its name, servers are still used, but the customer does not have to worry about provisioning, scaling, or maintaining them—the cloud provider handles all those operational tasks.
Serverless platforms automatically scale the backend resources based on the demand of incoming events (like an HTTP request, a database change, or a file upload), and the CSP manages the underlying infrastructure and associated security. The customer is responsible for the security of their application, managing access controls, and data encryption.
Embedded systems
Embedded systems are specialized computer systems designed to perform a dedicated function or a set of functions within a larger mechanical or electrical system. Unlike general-purpose computers (like a PC or server), an embedded system is typically real-time, resource-constrained, and built to be integrated and often completely hidden from the end-user.
Examples of embeded systems include electronic control units (ECUs) for engine management, navigation, airbag deployment, and entertainment systems, and smartwatches, smart thermostats, digital cameras, and even microwave oven components.
Embedded systems should be managed by emphasizing security throughout the entire product lifecycle and addressing their unique constraints (limited resources, real-time requirements, long lifecycles). Management focuses heavily on physical security, strong code integrity, and robust supply chain assurance.
High-Performance Computing systems
High-Performance Computing (HPC) systems are IT infrastructure solutions that aggregate computing resources to deliver significantly greater performance than a standard server or workstation, enabling users to solve massive, complex computational problems in science, engineering, and business.
HPC is often referred to as supercomputing and is defined by its ability to process massive datasets and perform complex calculations at extremely high speeds, often measured in petaflops (quadrillions of floating-point operations per second).
HPC is essential for applications that are too large, complex, or time-consuming for traditional computers:
Scientific Research: Genome sequencing, modeling protein structures, and simulating nuclear fusion.
Engineering and Design: Crash simulations for automobiles, computational fluid dynamics (CFD) for aircraft design, and weather forecasting.
Finance: Algorithmic trading and real-time fraud detection across millions of transactions.
AI/ML: Training large, complex Artificial Intelligence and Deep Learning models.
HPC systems are prime targets due to the high value of the data (intellectual property, sensitive research) and their complex, high-connectivity architecture. Although these types of systems often prioritize performance over stringent security controls, concerns about threats such as data exfiltration make securing them important.
Edge computing systems
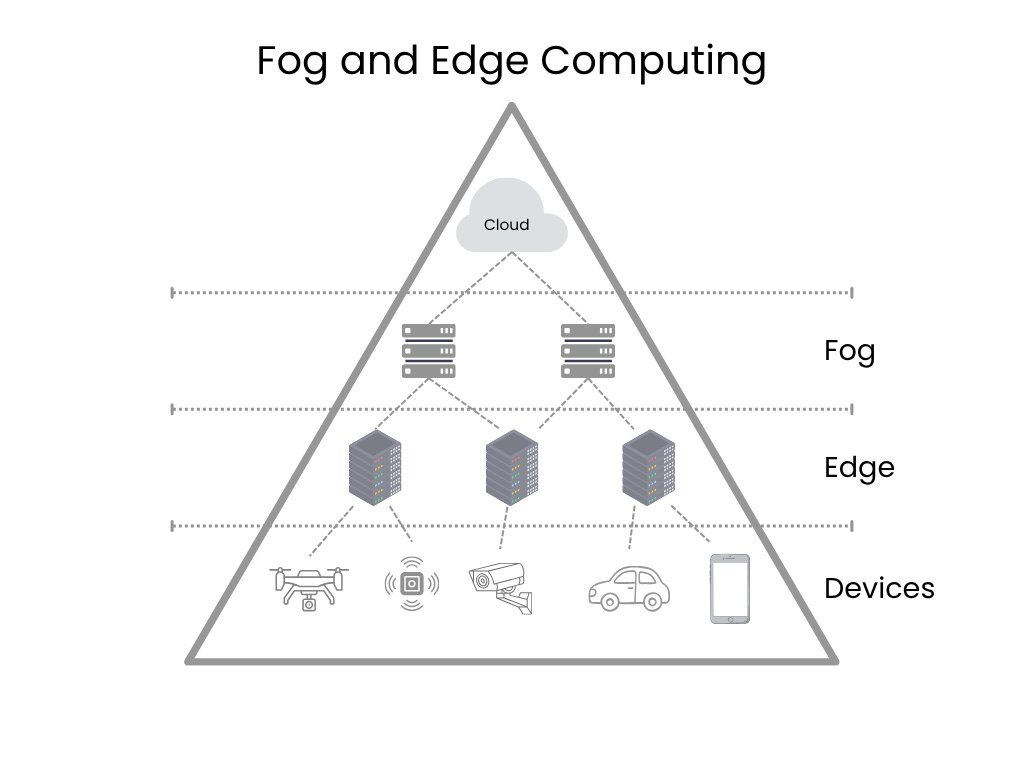
Edge and Fog Computing are decentralized computing models that extend the cloud closer to where data is generated, primarily to reduce latency and bandwidth usage. They are essential components of modern IoT and industrial systems.
Edge Computing is a networking philosophy that is focused on bringing computing as close to the source of data as possible in order to reduce latency and bandwidth use. In simple terms, edge computing means running fewer processes in the cloud and moving those processes to local places, such as on a user’s computer, an IoT device, or an edge server. Bringing computation to the network’s edge minimizes the amount of long-distance communication that has to happen between a client and server.
Goal: To perform immediate analysis and decision-making where the data is created (e.g., on a factory floor or a cell tower) instead of sending raw data to a central cloud data center.
Location: Devices closest to the physical action, such as sensors, routers, local servers, or industrial controllers.
Key Benefit: Extremely low latency and fast real-time response, critical for systems like autonomous vehicles or industrial control.
Examples include:
IoT devices: smart devices that connect to the Internet that run code on the device itself, rather than in the cloud, have better user interactions.
Medical monitoring devices: it is crucial for medical devices to respond in real time without waiting to hear from a cloud server.
Self-driving cars: autonomous vehicles need to react in real time, without waiting for instructions from a server.
Benefits include:
Cost saving: edge computing helps minimize bandwidth use and server resources.
Performance: moving processes to the edge reduces latency.
Fog Computing is essentially a larger, more distributed extension of cloud computing that sits as an intermediate layer between the edge and the central Cloud. It is sometimes described as a “cloud closer to the ground.”
Goal: to provide computation, storage, and networking services to end-user devices and aggregate data from multiple Edge devices before sending a summary to the central cloud.
Location: intermediate devices like regional gateways, aggregation points, or high-end routers.
Relationship to Edge: fog nodes manage and coordinate the edge devices, performing localized processing and analytics over a wider geographical area than a single Edge device.
Edge vs Fog: Edge computing processes data directly on or near the device where it’s generated, while fog computing acts as an intermediary layer, processing data on a local network or a gateway before it reaches the cloud. Edge is ideal for real-time responses, whereas fog is used for more complex, but still time-sensitive tasks, such as filtering data before it’s sent to the cloud.
One of the primary benefits of edge and fog computing from a security perspective is that they reduce the amount of data flowing to the cloud, which improves data privacy and reduces the risk of data breaches.
Both paradigms introduce unique security challenges because computing resources are moved outside the protected perimeter of a centralized data center.
Edge and Fog devices can be deployed in physically insecure or publicly accessible environments. They can be vulnerable to physical tampering, unauthorized access, or theft of the device itself, so physical security is important.
Network segmentation: use segmentation to isolate the Edge/Fog devices from mission-critical enterprise systems to reduce the impact of any compromise.
Data encryption and strong authentication: Use encryption for data both at rest and in transit. Use robust Public Key Infrastructure (PKI) and certificate-based authentication for machine-to-machine trust, eliminating reliance on passwords. Enforce unique identities for every device. Implement end-to-end encryption (e.g. Mutual Transport Layer Security or mTLS) for all communication. Use cryptographic techniques (like digital signatures or hashing) to verify the integrity of sensor data at the point of origin.
Regular patching: as with other critical devices, keep devices and systems patched.
Virtualized systems
Virtualization provides the means for running multiple operating systems on a single physical device or server. A virtual machine (VM) is a software emulation that splits a single physical computing device into many isolated computing environments, each with its allocated CPU, memory, storage, and operating system.
Some of the security considerations of virtualization include:
Hypervisor Security (the critical layer): the hypervisor is the foundation of the virtual environment. Its compromise means the compromise of every VM it hosts.
A Hypervisor Escape (or VM Escape) is the ultimate threat, where an attacker breaks out of their isolated VM and gains control of the hypervisor, allowing them to access, compromise, or monitor other co-resident VMs.
Control: The hypervisor must be hardened (e.g., removing unnecessary services/agents) and patched quickly to eliminate any vulnerabilities that could lead to an escape. Access to the hypervisor management interface must be strictly controlled, ideally using Multi-Factor Authentication (MFA) and a dedicated management network.
Storage and Network Security (virtual infrastructure): virtual components require security management just like physical ones.
Virtual Network Interface Card (vNIC) compromise or Virtual Switch misconfiguration can allow traffic to be inappropriately routed, letting an attacker tap into other VMs’ network segments.
VM Sprawl occurs when unmanaged or forgotten VMs accumulate, increasing the attack surface. These dormant VMs often lack patches and security agents.
Control: use network segmentation to isolate virtual machines, virtual firewalls. Network Access Control Lists (ACLs) should be applied to control inter-VM communication. Implement strict configuration management and automated asset inventory to prevent VM Sprawl. It’s also important, of course, to patch and secure the VMs themselves as well.
In part two, we’ll cover objective 3.6. If you’re on the CISSP journey, keep studying and connecting the dots, and let me know if you have any questions about this domain.

Couldn't agree more. Your point on integrating security early, especially with proactive threat modeling, is realy critical. Bolt-on approaches just don't work.