
The AI Paradigm Shift: Running It in the Wild (CISSP Domains 4, 5, 6 & 7)

Part 1 of this series was about governance and risk: who’s accountable for an AI system and how you decide what could go wrong. Part 2 was about the data: how to classify and protect the information a model learns from. Part 3 was about the build: the architecture and pipelines that turn that data into a finished model. Every part so far has been about getting a model ready. None of them touched what happens once you switch it on.
That’s where part 4 picks up. The model is now live, taking real traffic from real people, sitting behind APIs and inside your network. That changes the attack surface, and four CISSP domains answer the change: network security (Domain 4), identity (Domain 5), testing (Domain 6), and security operations (Domain 7).
You don’t need to be an ML engineer to follow this. The goal, as in the earlier parts, is to recognize a new category of risk and determine which kind of control addresses it. Most of these controls are ones you already know. They just point at something new.
Network Security and Endpoint Protection (Domain 4)
A live AI system talks to many things: APIs, cloud services, and clusters of GPUs that provide the actual compute. Every one of those connections is a door. Two of them lead somewhere you don’t want an attacker to go.
Model Extraction: Stealing the Model Through the Front Door
Imagine someone who can’t see your recipe but is allowed to taste the dish as many times as they want. Taste it enough, vary the orders enough, and eventually they can reproduce it at home. That is model extraction. The API is the tasting spoon.
In a model extraction attack, someone repeatedly queries your public endpoint, observing which inputs produce which outputs. Each answer tells them a little more about where the model draws its lines. Given enough queries, they can train their own local copy that behaves like yours. They walk away with your intellectual property without ever touching your database. This isn’t theoretical: researchers extracted production models from BigML and Amazon’s ML service with near-perfect fidelity using only the public prediction API (Tramèr et al., USENIX Security 2016), and the technique is now cataloged as Exfiltration via AI Inference API (AML.T0024) in MITRE ATLAS.
You don’t need the math to get the point. The more queries an attacker can fire at your endpoint, the better their copy gets. If nothing caps the number of queries, nothing caps the quality of the clone. So the fix is simple: limit how many queries any one caller can send, and you limit how good a copy they can build. That’s what rate-limiting does, and it’s the main defense here.
The Controls
Protecting a model endpoint is mostly familiar network security pointed at a new target.
TLS 1.3 with mutual authentication (mTLS). Encrypt everything in transit, and use mTLS (both sides prove who they are with certificates, no passwords) for internal calls between your application services and the AI engines behind them.
Micro-segmentation. Put the GPU clusters in their own Virtual Private Clouds, block direct inbound traffic, and force every query through an authenticated API gateway. This is the same network segmentation from Domain 4 you already know, pointed at compute instead of subnets.
Rate-limiting and query baselining. Set a normal range for how a human interacts with the endpoint. When something blows past that range, the way an extraction attack has to, block it automatically. This is the direct counter to the model-theft problem above.
Identity and Access Management (Domain 5)
Access control in an AI environment splits the same way it always has. Authentication asks, “Are you who you say you are?” Authorization asks, “Are you allowed to touch this model or this dataset?” The twist is that more and more of the things asking for access aren’t people.
Least Privilege, Need-to-Know, and Just-in-Time Access
The old principles still hold. They just apply to model weights and training jobs now.
Lock down the model registry. Treat read, write, and modify rights on model weights like you’d treat write access to production code, because that’s what they are. Only your automated build tools should be able to promote a model. People shouldn’t be editing neural parameters by hand any more than they’d hand-edit a production binary.
Just-in-time retraining access. Don’t hand engineers a standing permission to retrain. Make them request it when they need it, and revoke it automatically when the job finishes. This is the same just-in-time privilege you’d use for admin access, applied to the training pipeline.
Identity for Autonomous Agents
Here’s where the familiar model starts to crack. AI workflows are moving toward autonomous agents: software that queries databases, calls APIs, and takes actions on an employee’s behalf without a human in the loop for each step. User-based identity wasn’t built for that.
Give every agent its own identity. Each autonomous agent needs a unique cryptographic machine identity (a service account or OAuth client credentials of its own). Without it, you can’t prove which agent did what, and non-repudiation falls apart the moment something goes wrong.[5]
Use ABAC, not just RBAC. Role-Based Access Control checks who you are, like a badge at a door. Attribute-Based Access Control checks who you are and what you’re doing, what you’re touching, where the request came from, and how risky it looks right now, all before it says yes (NIST SP 800-162 is the canonical definition). For an agent whose job changes minute to minute, the badge alone isn’t enough.
Security Assessment and Testing (Domain 6)
Your existing tools have a blind spot here. A vulnerability scanner reads code. A static analyzer reads code. Neither one can tell you that your model will happily ignore its own safety rules when a user phrases the request the right way. There’s no buggy line of code to find. The weakness lies in how the model handles language, so the only way to catch it is to deliberately attack it with words.
The AI Red Teaming Program
AI red teaming is testing a live model the way an attacker would, hunting for inputs that cause it to misbehave or reveal what it shouldn’t. According to a recent NIST post, you can’t lock a model down once and walk away. NIST senior scientist Apostol Vassilev published a 2026 proof that no finite set of guardrails is universally robust against adversarial prompts, and his takeaway, in a sentence, is the case for red teaming: “You have to commit to a constant search for weaknesses and stay ahead of attackers.” It’s an offensive mindset aimed at a system that traditional testing treats as a black box.
Red teaming goes after three main things. Model hijacking is taking control of how the model behaves, bending its outputs, or repurposing it for something it was never meant to do. Model extraction, the theft attack from Domain 4 above, reverse-engineers the model itself. Prompt injection abuses the input channel to override the system prompt and the rules baked into it. A good program probes for all three.
Run it as a real program, not a one-off. AI red-teaming is one of the testing methodologies that NIST formally recommends in the Measure function of its Generative AI Profile (NIST AI 600-1), which also provides the Govern/Map/Measure/Manage structure for handling what you find. Document those findings in a central risk register and fix things in the order that business impact dictates, not the order you found them in.
Security Operations (Domain 7)
Your SOC can’t defend what it can’t see, and a live AI system generates a kind of traffic the SOC has never had to watch before: prompts going in, generated responses coming out, agents acting on their own. Domain 7 is about getting eyes on it all.
The Defensive Tooling Got an Upgrade Too
The same AI that opened new attack surfaces is now built into the tools that defend them. In four categories of security tooling, AI was once an optional add-on. Now it comes built in, and it’s worth knowing what each one does:
SIEM aggregates and correlates logs. The AI layer spots anomalies across event streams and reduces alert fatigue by separating real signals from the noise.
SOAR automates the response once a threat is detected. Agentic AI is what’s driving it now: systems that take defined actions without waiting for a human to push the button.
XDR ties detection together across endpoints, networks, clouds, and apps. The AI connects dots across data sources that no human could correlate by hand at that volume.
UEBA monitors behavior and flags deviations from a baseline for users and service accounts alike. It catches the slow compromise that never trips a single alarm, the drift that signature-based detection sleeps right through.
These extend your existing Domain 7 controls; they don’t replace them. For the exam, know what each one does and where AI augments the analyst rather than replaces their judgment. UEBA is the answer worth memorizing: it’s the canonical “anomaly over time” pick when a scenario rules out signature-based detection.
Watching What Goes Out: Continuous Monitoring and DLP
The everyday risk here isn’t an attacker. It’s a well-meaning employee pasting source code or customer PII into a public chatbot. This already happened at Samsung: within weeks of allowing ChatGPT, engineers leaked semiconductor source code and internal meeting notes into it three separate times, and the company banned the tool outright (TechRadar, 2023).
Inline DLP and CASB. Put Data Loss Prevention gateways and Cloud Access Security Brokers (a CASB sits between your users and the cloud service, inspecting what crosses) in line with outbound prompts. When sensitive strings show up, a credit card number, an internal code header, the payload gets blocked or tokenized before it leaves the building.
Semantic logging. Normal logs record events: who logged in, what ran. AI auditing needs more than that. Record the actual prompt strings and the model’s responses, then run automated analysis over them to flag data leakage, social engineering, or an attack in progress. You’re logging meaning, not just events.
Watching the Model Itself: Model Drift
Even with no attacker anywhere near it, an AI model gets worse over time. Picture a guard dog trained on last year’s burglars. The burglars changed their methods. The dog didn’t. On paper, it’s the same deterrent. On the street, they are less effective. That’s model drift: production data slowly stops looking like the training data, and accuracy bleeds away. A threat-detection model trained on old attack patterns gets weaker every time attackers change their tactics.
For Domain 7, drift is a continuous-monitoring problem with three parts:
Detection. Compare live performance against your baseline numbers (accuracy, precision, recall, false-positive rate). A statistically real drop triggers a look.
Indicators. Shifts in the input feature distribution, a sudden change in the confidence-score histogram, rising false positives, and outputs drifting away from ground truth (when you have it) all point the same way.
Response. Decide your retraining trigger in advance. Some teams retrain on a schedule, others when drift crosses a threshold. Either works, as long as it’s a written playbook and not a judgment call made in a panic.
Drift is the quiet sibling of data poisoning. Poisoning corrupts the model on purpose. Drift happens because the world moved on. Both give you wrong answers, both need monitoring, and both live in the Domain 7 playbook.
When It Breaks: Incident Response
Your IR plan needs a few AI-specific moves.
Model quarantine. Write the playbook for isolating a model you think has been poisoned. The moment it’s suspect, pull the container offline and route inference to a clean cold-standby copy. Treat it like isolating any other compromised host, just faster, because the model keeps answering until you stop it.
Automated guardrails. Put rule-based limits around the inference API that act as a circuit breaker. When an output looks wrong in shape or content, the guardrail catches it before it ever reaches the user.
The Part That Stays Human: Context and Critique
There’s one risk in this whole series that no control in any domain can fix for you. AI is taking over the routine middle of knowledge work, the everyday analysis that used to be how people built their expertise in the first place. As it takes that work over, people stop checking its output. And when you stop checking the machine’s work, you slowly stop understanding it. The skill hollows out from the inside. This isn’t a hunch. Human-factors research has documented “automation complacency” for years: when a system is usually right, people stop scrutinizing it, miss its failures, and the effect hits experts as well as novices and doesn’t wash out with practice (Parasuraman & Manzey, Human Factors, 2010).
That’s a security problem, not just a career one. A tool can’t be held accountable in a courtroom or an audit. You can. So the human has to stay in the loop on purpose, through a discipline we can call the Context and Critique Rule. It adds a little friction back in, on purpose, in three steps:
Evidence. Treat every AI output as raw, unverified data. Not an answer yet.
Cognition. Check it against what you actually know: the business rules, the compliance lines, the security frameworks in your head.
Discernment. Take the “Human Pause.” Stop, think, and decide. Because the liability falls on you no matter what the model says, you sign off on accuracy and security before anything moves forward.
The shift this series has been building toward is from doing the work to directing it. As a professional, you’re more valuable the better you understand and orchestrate these systems. The technology is a tool. It isn’t a teammate, and it can’t carry the blame when something breaks.
Pulling the Series Together
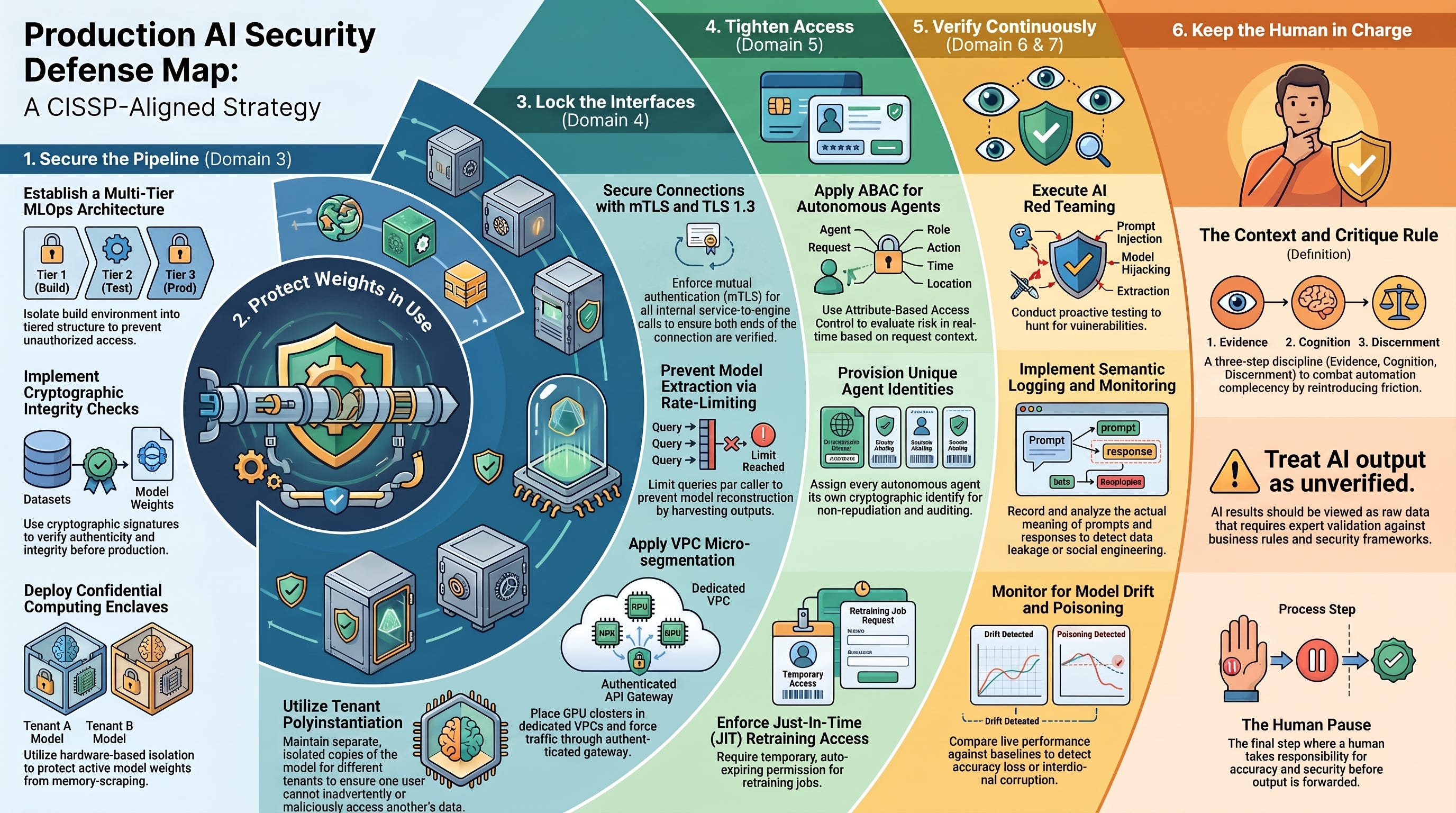
Across four parts, the throughline has been the same: AI doesn’t get its own CISSP domain, it lands in all of them, and the controls you already know mostly still apply once you see where they point. To put it in one map:
Secure the pipeline (Domain 3). Isolated, multi-tier MLOps architecture with cryptographic checks on datasets and model weights.
Protect the weights in use (Domain 3 & 8). Confidential Computing enclaves and polyinstantiation (separate, isolated copies so one tenant can never read another’s data) to keep model weights safe while they’re running.
Lock the interfaces (Domain 4). TLS 1.3, VPC micro-segmentation, and rate-limiting against model extraction.
Tighten access (Domain 5). Least privilege and need-to-know on the registries and training jobs, with ABAC for anything autonomous.
Verify continuously (Domain 6 & 7). A real AI red teaming program alongside semantic monitoring, inline DLP, and automated output guardrails.
Keep the human in charge. The Context and Critique Rule and the Human Pause, on every team.
Get the first five right, and you’ve got a defensible AI security posture. Get the sixth right, and you’ve got people who can still tell when the first five have failed. That last one is the whole point. Every other control in this series protects the system. This one protects your ability to know whether the system is lying to you.