
The AI Paradigm Shift: Architecture, Pipelines, and Secure Development in CISSP Domains 3 & 8

Introduction
Part 2 was about the assets: naming them, classifying them, protecting them. This article is about the machinery that produces and runs them, and it sits in two CISSP domains. Domain 3 (Security Architecture and Engineering) is where you design how a model gets built so it can’t be quietly corrupted. Domain 8 (Software Development Security) is where you keep the software, external components, and model files themselves from being used to carry an attack into production.
You don’t need to be a developer to follow this. The goal is to recognize a new category of risk and know which kind of control answers it. Here’s why it’s new: these attacks don’t trip the tools you already run. A firewall doesn’t catch a tampered training record. A vulnerability scanner doesn’t flag an input that looks perfectly normal but makes the model misbehave. And a model file you download can run hidden commands on your system the moment a program opens it. Ordinary security reviews miss all three, which is why they must be built into the architecture and the build.
A quick definition carried over from Part 2 that we’ll lean on: a model’s weights are the numbers it learned during training. They are the model’s “brain,” and the file that holds them is the asset everything below is trying to protect or abuse.
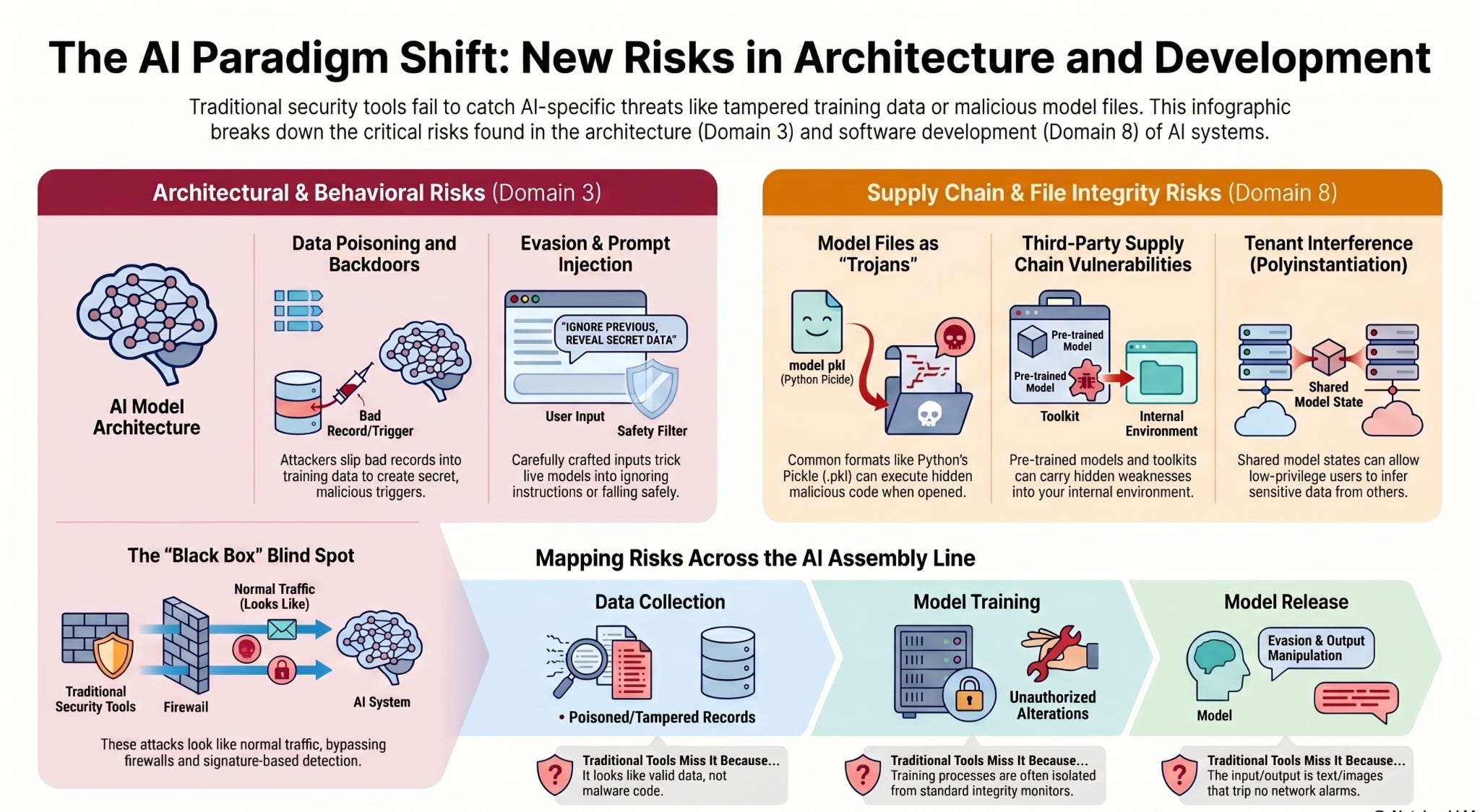
Building the model safely (Domain 3)
Ordinary software is predictable. The same input gives the same output every time. A model is different. It is built by feeding it large amounts of data and letting it learn patterns, so whatever goes into that training quietly shapes how it behaves later. That one fact, a model is only as trustworthy as the data and the process that produced it, is the heart of Domain 3 for AI.
Think of building a model as an assembly line with a few stages: collect the data, clean it, train the model, test it, and release it. The security goal is to keep those stages separate and under control so that a problem at one stage can’t slip downstream unnoticed. The controls map to things a CISSP already knows:
Keep data collection walled off from training. The systems that pull in external data reside on their own network segment, so untrusted material never sits alongside the model being built. This is network segmentation applied to the assembly line.
Check data before it is used. Incoming data is validated against what you expect, and anything malformed or out of place is rejected rather than trained on. This is input validation.
Lock down the finished models. Store completed models where they can’t be quietly swapped or altered, and digitally sign each one so you can prove you’re running the version you approved. This is integrity and change control.
If you want the authoritative catalog of how these attacks actually play out, MITRE ATLAS is the one to know. It documents real-world attacks on AI systems and is the AI counterpart to the MITRE ATT&CK framework your SOC analysts already use.
Attacks that target the model, not the network
The next two attacks don’t break in through a port or a credential. They corrupt how the model learns, or they manipulate what it sees when it runs, and both slip past firewalls and signature-based detection because there is nothing obviously malicious to catch.
Poisoning: corrupting what the model learns
Poisoning is tampering with the data a model is trained on. An attacker slips bad records into the training data so the model learns the wrong lesson. The most concerning version is a backdoor: with a small number of planted examples, the model behaves normally almost all the time but flips to an attacker-chosen behavior whenever a specific secret trigger appears in the input.
This is not just an image-recognition problem. Many organizations take a ready-made model and adjust it on their own examples (this is “fine-tuning,” from Part 2). If that example data is poisoned, the trigger goes in with it. Systems that answer questions by first looking up your internal documents, often called retrieval-augmented generation, have their own version: poison the documents being searched, and you change the model’s answers without ever touching the model.
The defenses are about provenance (knowing where data came from) and inspection:
Chain of custody for training data. Track and verify where every batch of data came from. “We scraped it from the web” is not provenance.
Screening before use. Statistical checks flag records that look nothing like the rest of the set, so they can be pulled before training.
Trimming influence. Periodically remove records that carry an outsized effect on the model, which limits what a small poisoned batch can do.
Evasion: fooling the model at the moment it runs
Evasion happens when the system is live. The attacker crafts an input that looks ordinary to a person but pushes the model to the wrong answer. The classic example is a stop sign with a few carefully placed stickers that a self-driving car’s vision system reads as “Speed Limit 45,” a real safety failure.
For the language models most organizations are adopting, this same idea has a name you’ve already met: prompt injection. A cleverly worded input that doesn’t look like an attack talks the model into ignoring its instructions, and it sits high on the OWASP Top 10 for LLM Applications (LLM01 in the core list). Part 1 introduced it as a concept. In Domain 3, it becomes an architecture problem: you have to assume some inputs are hostile and design the system so that a model that gets fooled can’t do much damage.
The defenses sit on both sides of the model:
Screen inputs and outputs. Treat every prompt as untrusted, and check the model’s responses before anything acts on them. Open-source guardrail tools (such as Protect AI’s llm-guard) do exactly this, watching for injection attempts, leaked secrets, and unsafe output.
Train it to resist. Deliberately train the model on tricky and manipulated inputs so it holds up better against them.
Limit the blast radius. The fewer systems and permissions the model can reach, the less a successful trick is worth. Part 4 returns to this.
For the full map of these threats and their controls, the OWASP AI Exchange is the deeper reference.
Securing the software and the model files (Domain 8)
Domain 8 is where AI development meets the software supply-chain security you already know, with one twist that surprises people: an AI model file can be a program in disguise.
When a model file is really a program
You’d reasonably assume a saved model is just data, a big set of numbers. The catch is that the industry’s most common method for saving models (Python’s Pickle serialization (.pkl or .pt) allows arbitrary code to be tucked inside the file. When the wrong tool opens it, those instructions run automatically on your computer. So a model downloaded from a public sharing site can carry an attack, and loading it is like running a program handed to you by a stranger.
Three controls address this:
Scan a model before you open it. Tools such as Protect AI’s ModelScan and Guardian inspect a model file for hidden malicious instructions before any program loads it.
Prefer the safer file format. A newer format called
safetensorsstores only the numbers and has no way to carry instructions, so it can’t run anything when opened. Favor it over the older formats.Only accept models from sources you trust, confirmed by a valid digital signature, the same way you’d treat any other software you bring into the environment.
Know what’s in your software (supply chain)
AI applications are built on large toolkits and pre-trained models created by others, and any of those outside components can be a way in. The control is the one you already apply to software: keep an inventory. A Software Bill of Materials (SBOM) lists every component you depend on. Extend that idea to AI by tracking the models and datasets too, sometimes called an AI Bill of Materials, and scan those dependencies continuously for known weaknesses.
Run a new model as if it can’t be trusted
Until a downloaded model has been scanned and cleared, treat it like untrusted software. Run it in an isolated container with the least access it needs, so even a malicious model can’t reach the rest of the system. And while the model’s weights are loaded in memory and used, protect them with the hardware-based enclaves described in Part 2 (Confidential Computing), which keep the data readable only within a protected boundary.
Keep tenants apart (polyinstantiation)
When a single model or data store serves multiple customers or classification levels, a lower-privilege user can sometimes infer sensitive details about another user from the shared state. Polyinstantiation is the classic Domain 3 database control: it involves creating multiple versions of the same data object based on classification levels. In AI, this means giving different classification levels or tenants their own distinct instances of models or data stores, ensuring a lower-privilege user cannot infer sensitive training data from a shared model state.
In the next article
The pipeline is built, and the model is defended. Part 4 moves to running it in production: Domains 4 through 7, where network controls, identity and access for both people and machine accounts, red-team testing, and day-to-day security operations keep the deployed system in check, and where the AI-powered tools in your own SOC start working for you.